(This post has been updated so make sure you read all the way to the bottom.)
Are non-linking URLs (pasted URLs) seen as links by Google? There’s long been chatter and rumor that they do among various members of the SEO community. I found something the other day that seems to confirm this.
Google Webmaster Tools Crawl Errors
I keep a close eye on the Crawl Errors report in Google Webmaster Tools with a particular focus on ‘Not found’ errors. I look to see if they’re legitimate and whether they’re linked internally (which is very bad) or externally.
The place to look for this information is in the ‘Linked from’ tab of a specific error.
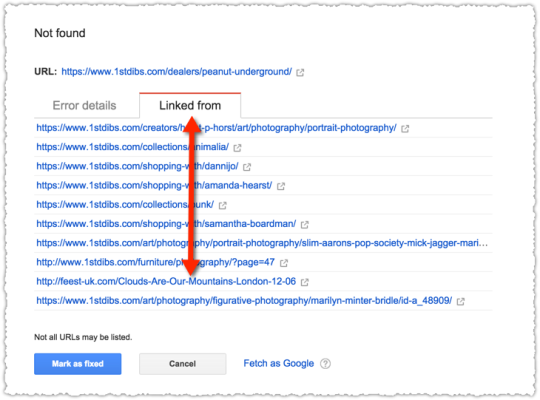
Now, all too often the internal links presented here are woefully out-of-date (and that’s being generous.) You click through, search for the link in the code and don’t find it. Again and again and again. Such was the case here. This is extremely annoying but is a topic for another blog post.
Instead let’s focus on that one external link. Because I figured this was the reason Google continued to return the page as an error even though 1stdibs had stopped linking to it ages ago.
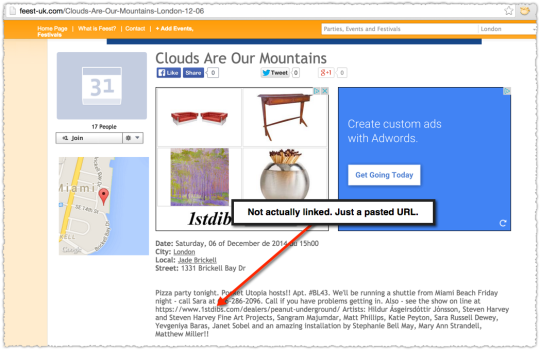
That’s not a link! It’s a pasted URL but it’s not a link. (Ignore the retargeted ad.) Looking at the code there’s no <a> tag. Maybe it was there and then removed but that … doesn’t seem likely. In addition, I’ve seen a few more examples of this behavior but didn’t capture them at the time and have since marked those errors as fixed. #kickingmyself
Google (or a tool Google provides) is telling me that the page in question links to this 404 page.
Non-Linking URLs Treated As Links?

It’s not a stretch to think that Google would be able to recognize the pattern of a URL in text and, thus, treat it as a link. And there are good reasons why they might want to since many unsophisticated users botch the HTML.
By treating pasted URLs as links Google can recover those citations, acknowledge the real intent and pass authority appropriately. (Though it doesn’t look like they’re doing that but instead using it solely for discovery.)
All of this is interesting from an academic perspective but doesn’t really change a whole lot in the scheme of things. Hopefully you’re not suddenly thinking that you should go out and try to secure non-linking URLs. (Seriously, don’t!)
What’s your take? Is this the smoking gun proof that Google treats non-linking URLs as links?
[Update]
Apparently John Mueller confirmed this in a Google+ Hangout back in September of 2013. So while seeing it in Google Webmaster Tools might be new(ish), Google clearly acknowledges and crawls non-linked URLs. Thanks to Glenn Gabe for pointing me to this information.
In addition, Dan Petrovic did a study to determine if non-linking URLs influenced rankings and found it likely that they did not. This makes a bit of sense since you wouldn’t be able to nofollow these pasted URLs, opening the door to abuse via blog comments.
The Next Post: My Favorite SEO Tool
The Previous Post: Aggregating Intent

1 trackbacks/pingbacks
Comments About Non-Linking URLs Seen As Links
// 26 comments so far.
Yasir // March 20th 2015
Yes, I have seen this happening for some time now. I first came across unlinked URLs when I was going through the ‘Links to your site’ for one of website.
AJ Kohn // March 20th 2015
Good to know others are seeing the behavior Yasir.
Jamie // March 20th 2015
I have seen the same thing with my crawl errors … never really thought much of it until now.
AJ Kohn // March 20th 2015
Thanks for the confirmation Jamie. It’s not really actionable but it is … interesting.
Kane Jamison // March 20th 2015
I’ve noticed one as long as 2 years ago in GWT. Prob about the same time as that JM confirmation video. It was also for a complete & text-only url starting with “http://…”
AJ Kohn // March 20th 2015
Good to know Kane. I’ve asked a few folks if there’s been a test on whether these pasted URLs do or do not pass authority. John indicated they don’t but it should be a relatively straight-forward thing to test.
Not that I have the time to do it but there are other groups who could. Yet, what would you do with that knowledge one way or the other? It’d be interesting to know but will it change how you work? Probably not.
Victor Pan // March 20th 2015
I’m also aware of this.
Note that it is good for indexation and discovery only. But of course that doesn’t stop the # of people filling the web with non-linking naked urls like it’ll move rank.
Actually I haven’t tested that so I shouldn’t be too quick to judge, but I can’t imagine it being the case.
AJ Kohn // March 20th 2015
Correct Victor. I’d actually chatted with some folks a couple of years ago who were flirting with this as a black hat technique.
But those pasted URLs would need to pass authority for it to really work. Mr. Mueller, who I like a great deal, said they didn’t as of September 2013. I still think it would be an intriguing test, though it would only prove something from a purely academic perspective.
Jon // March 20th 2015
Hi AJ. I thought this was common knowledge. They’ve publicly (I think) been open about using them for discovery, because it means that a URL they may bit have crawled DOES exist so is worth them checking out.
I think in a perfect world Google would like to treat them as endorsements (because they are), but it would undo the nofollow attribute overnight, making blog comments fertile ground again.
Jon
AJ Kohn // March 20th 2015
Maybe it is Jon. When Glenn pointed me at that post I remembered it all over again in a ‘oh yeah, that’s right’ type of way. I must be getting old. And it doesn’t help that there’s little real-world application to the knowledge.
Agreed that Google likely wants to treat them as an endorsement because, as you say, they really are at the end of the day. But you astutely point out that it would open the door for astroturfing comments without fear of getting nofollowed.
Jessica // March 21st 2015
It’s exceptional news. I was totally unaware of this. Thanks for your informative article.
Chase Billow // March 21st 2015
Re: Kane Jamison’s comment – does this mean URL’s pasted without the “http://” do not get the same treatment? ie. – “www.example.com” and “example.com”
AJ Kohn // March 22nd 2015
Chase,
It’s my understanding that Google will crawl all of the variations you mentioned.
Nevyana Karakasheva // March 23rd 2015
Hi AJ,
I’ve noticed this a while ago when I was skimming through the WMT inbound link profile of a client. Interesting as it is save from nonlinking URLs, I’ve also seen partial non-html urls, i.e. website mentions without http:// (root domain type like mysite.com), which was rather interesting.
I am not aware as to whether it is been discussed already, but another curious example of hard-to-locate backlinks is the hidden in the source code of a given article comment links.
Such hidden comment links are often associated with pages that are few years old: my guess is that during a site upgrade the site owner has decided to either close the comments to the old post or to hide them altogether. In this case the comments are often enclosed in a comment tag in the page source code and are no longer visible for the site visitor, but are crawlable.
I am not sure as to why Google lists them in their “links to Your Site” database: whether because they have been crawled a long time ago and because WMT data is stale, or because the bot still sees them and considers them as active links.
This is an interesting issue to consider, especially if the hidden links are followed ones and are in-text links inserted in the regular page content.
AJ Kohn // March 23rd 2015
Lots of great insight there Nevyana. Your comment about the links that are no longer visible because comments have been closed or disabled is intriguing. I mention in the post that sometimes Google will crawl what seems like ancient versions of a site and it’s in those instances that these non-visible links might come roaring back to life.
Why Google decides to do this is still a bit of a mystery to me. Perhaps it’s Google’s way of dealing with linkrot, which is a larger problem than many realize.
Andy Drinkwater // March 23rd 2015
Seen this many time and never given it much thought outside of the fact it’s a ‘mention’ of sorts and thereby worthy of some information to Google.
Great article AJ!
James // March 23rd 2015
We had picked this up whilst conducting a local SEO study based around citations. As a citation we concluded it did have an impact on rankings, perhaps not in the same way as an actual link but certainly as with attribution of a citation.
AJ Kohn // March 23rd 2015
Interesting James. I agree that this has the most relevance to Local SEO and the way in which citations might convey some sort of authority. One wonders how you might assign that authority without it passing link value since the implications of it passing link value would open up the door to lots of spam.
Bob Gladstein // March 23rd 2015
I’ve been seeing a ton of these lately. I’m working on a site that adds an attribute to the code of their links that looks a lot like a URL, but isn’t. It’s there for click-tracking purposes (it feeds the data to SiteCatalyst), which is pretty useful if a given page links to another page more than once. The attribute on the first link from page-a to page-b will be something like “page-b_1” and on the second link it will be something like “page-b_2”.
But now I’ve got WMT reporting thousands of internal 404s because it claims that page-a is linking to both page-b_1 and page-b_2, both of which get a 404 response when Googlebot requests them.
AJ Kohn // March 23rd 2015
Yes Bob, I’ve seen some of this behavior as well. Google will execute anything in the site code that looks like a URL fragment. They’re essentially crawling from a relative and not absolute URL perspective. I’ve had to have many dev teams remove those references or block them via robots.txt so those internal 404s don’t get generated. #annoying
Ashley McNamara // March 23rd 2015
I recently discovered this on my company’s site so happy to hear some confirmation. Before I came on board, they un-linked an entire section of the site but it still gets organic traffic. I discovered in a site crawl that the non-linked urls still exist in the source code on some pages. So the only way users can reach these pages is via organic search, but google keeps favoring them for some odd reason!
AJ Kohn // March 24th 2015
Interesting Ashley. So the pages are now orphans but technically still exist in the code. Google may simply see those links from a non-JavaScript perspective, though I’d have to see it to know for sure.
Ashley McNamara // March 24th 2015
Yup, we orphaned this whole /related-lots/ section but you can see them in the source code of certain pages like this one: http://www.invaluable.com/auction-lot/early-american-imprints-benezet,-anthony-.-s-39-c-57561f0e5b
JR Oakes // March 25th 2015
AJ,
Nice post. Just curious… Did you cross-reference with “Links to your site” > Sample (or Latest) Links?
AJ Kohn // March 25th 2015
JR,
I did not do that in this case but from the comments here and on Twitter it seems like these do show up there as well.
Eric Ward // April 02nd 2015
A.J. – Have the utmost respect for your work, so please enjoy the following. Below is link to a presentation I made 13 years ago at SES Boston, where I mentioned for the first time the idea that unclickable URLs could still matter. This URL below has not been public since then.
http://www.ericward.com/s/sesboston/boston2002.html
I feel really old now.
Sorry, comments for this entry are closed at this time.
You can follow any responses to this entry via its RSS comments feed.