Dog goes woof
Cat goes meow
Bird goes tweet
and mouse goes squeak
Cow goes moo
Frog goes croak
and the elephant goes toot
Ducks say quack
and fish go blub
and the seal goes ow ow ow ow ow
But theres one sound
That no one knows
What does the hummingbird say?
What Does The Hummingbird Say?
For the last month or so the search industry has been trying to figure out Google’s new Hummingbird update. What is it? How does it work? How should you react.
There’s been a handful of good posts on Hummingbird including those by Danny Sullivan, Bill Slawski, Gianluca Fiorelli, Eric Enge (featuring Danny Sullivan), Ammon Johns and Aaron Bradley. I suggest you read all of these given the chance.
I share many of the views expressed in the referenced posts but with some variations and additions, which is the genesis of this post.
Entities, Entities, Entities
Are you sick of hearing about entities yet? You probably are but you should get used to it because they’re here to stay in a big way. Entities are at the heart of Hummingbird if you parse statements from Amit Singhal.
We now get that the words in the search box are real world people, places and things, and not just strings to be managed on a web page.
Long story short, Google is beginning to understand the meaning behind words and not just the words themselves. And in August 2013 Google published something specifically on this topic in relation to an open source toolkit called word2vec, which is short for word to vector.
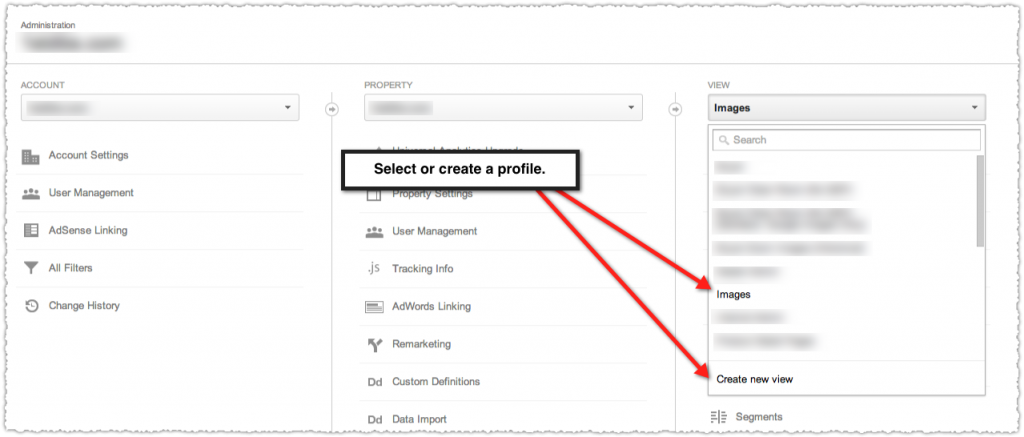
Word2vec uses distributed representations of text to capture similarities among concepts. For example, it understands that Paris and France are related the same way Berlin and Germany are (capital and country), and not the same way Madrid and Italy are. This chart shows how well it can learn the concept of capital cities, just by reading lots of news articles — with no human supervision:
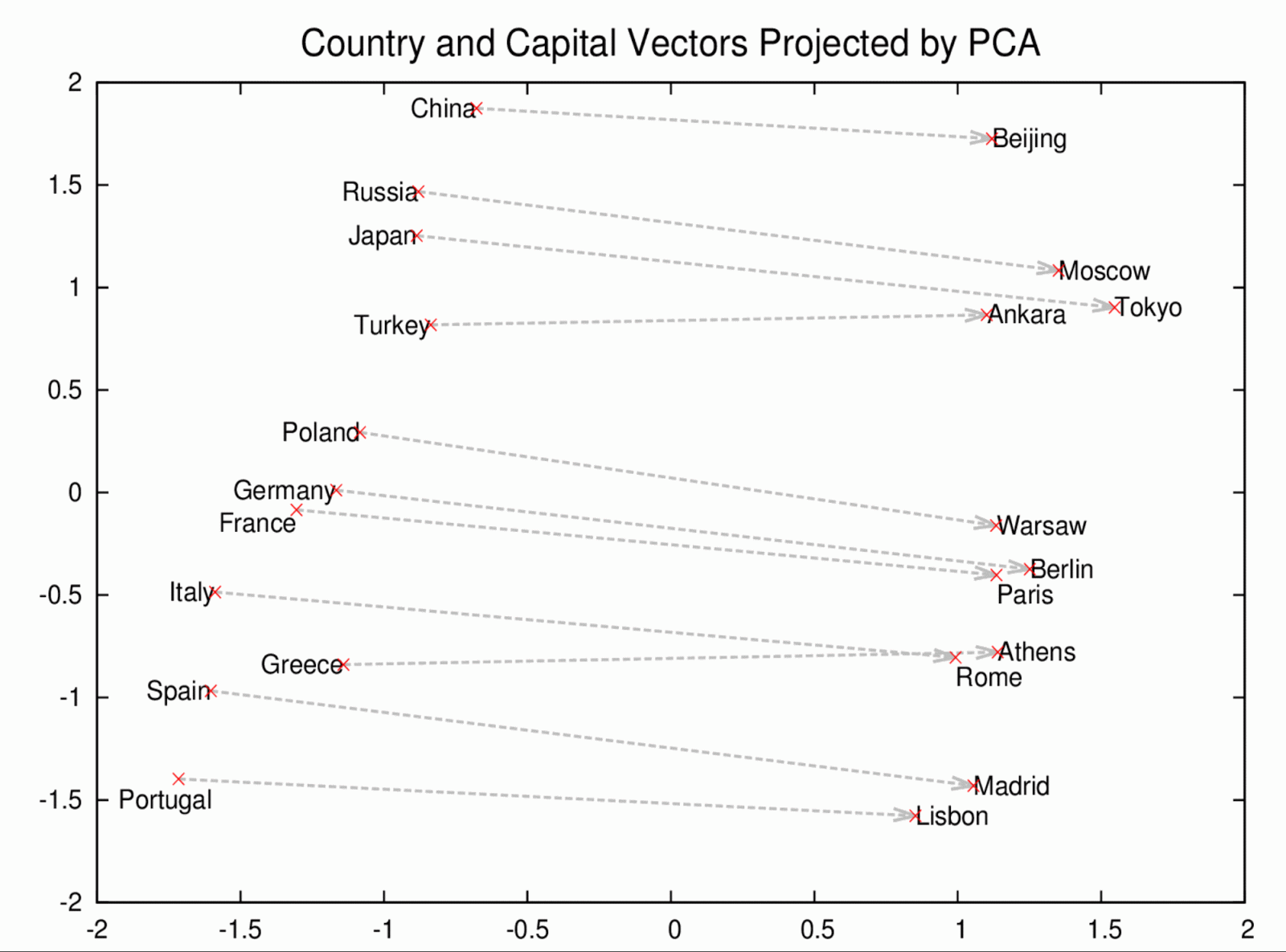
So that’s pretty cool isn’t it? It gets even cooler when you think about how these words are actually places that have a tremendous amount of metadata surrounding them.
Topic Modeling
It’s my belief that the place where Hummingbird has had the most impact is in the topic modeling of sites and documents. We already know that Google is aggressively parsing documents and extracting entities.
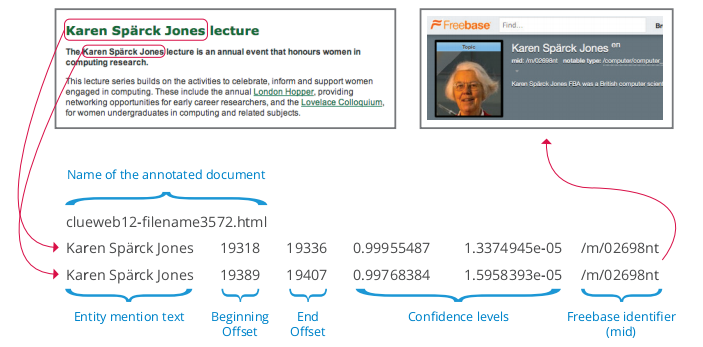
When you type in a search query — perhaps Plato — are you interested in the string of letters you typed? Or the concept or entity represented by that string? But knowing that the string represents something real and meaningful only gets you so far in computational linguistics or information retrieval — you have to know what the string actually refers to. The Knowledge Graph and Freebase are databases of things, not strings, and references to them let you operate in the realm of concepts and entities rather than strings and n-grams.
Reading this I think it becomes clear that once those entities are extracted Google is then performing a lookup on an entity database(s) and learning about what that entity means. In particular Google wants to know what topic/concept/subject to which that entity is connected.
Google seems to be pretty focused on that if you look at the Freebase home page today.

Tamar Yehoshua, VP of Search, also said as much during the Google Search Turns 15 event.
So the Knowledge Graph is great at letting you explore topics and sets of topics.
One of the examples she used was the search for impressionistic artists. Google returned a list of artists and allowed you to navigate to different genres like cubists. It’s clear that Google is relating specific entities, artists in this case, to a concept or topic like impressionist artists, and further up to a parent topic of art.
Do you think that having those entities on a page might then help Google better understand what the topic of that page is about? You better believe it.
Based on client data I think that the May 2013 Phantom Update was the first application of a combined topic model (aka Hummingbird). Two weeks later it was rolled back and then later reapplied with some adjustments.
Hummingbird refined the topic modeling of sites and pages that are essential to delivering relevant results.
Strings AND Things

This doesn’t mean that text based analysis has gone the way of the do-do bird. First off, Google still needs text to identify entities. Anyone who thinks that keywords (or perhaps it’s easier to call them subjects) in text isn’t meaningful is missing the boat.
In almost all cases you don’t have as much labeled data as you’d really like.
That’s a quote from a great interview with Jeff Dean and while I’m taking the meaning of labeled data out of context I think it makes sense here. Writing properly (using nouns and subjects) will help Google to assign labels to your documents. In other words, make it easy for Google to know what you’re talking about.
Google can still infer a lot about what that page is about and return it for appropriate queries by using natural language processing and machine learning techniques. But now they’ve been able to extract entities, understand the topics to which they refer and then feed that back into the topic model. So in some ways I think Hummingbird allows for a type of recursive topic modeling effort to take place.
If we use the engine metaphor favored by Amit and Danny, Hummingbird is a hybrid engine instead of a combustion or electric only engine.
From Caffeine to Hummingbird

One of the head scratching parts of the announcement was the comparison of Hummingbird to Caffeine. The latter was a huge change in the way that Google crawled and indexed data. In large part Caffeine was about the implementation of Percolator (incremental processing), Dremel (ad-hoc query analysis) and Pregel (graph analysis). It was about infrastructure.
So we should be thinking about Hummingbird in the same way. If we believe that Google now wants to use both text and entity based signals to determine quality and relevance they’d need a way to plug both sources of data into the algorithm.
Imagine a hybrid car that didn’t have a way to recharge the battery. You might get some initial value out of that hybrid engine but it would be limited. Because once out of juice you’d have to take the battery out and replace it with a new one. That would suck.
Instead, what you need is a way to continuously recharge the battery so the hybrid engine keeps humming along. So you can think of Hummingbird as the way to deliver new sources of data (fuel!) to the search engine.
Right now that new source of data is entities but, as Danny Sullivan points out, it could also be used to bring social data into the engine. I still don’t think that’s happening right now, but the infrastructure may now be in place to do so.
The algorithms aren’t really changing but the the amount of data Google can now process allows for greater precision and insight.
Deep Learning

What we’re really talking about is a field that is being referred to as deep learning, which you can think of as machine learning on steroids.
This is a really fascinating (and often dense) area that looks at the use of labeled and unlabeled data and the use of supervised and unsupervised learning models. These concepts are somewhat related and I’ll try to quickly explain them, though I may mangle the precise definitions. (Scholarly types are encouraged to jump in an provide correction or guidance.)
The vast majority of data is unlabeled, which is a fancy way of saying that it hasn’t been classified or doesn’t have any context. Labeled data has some sort of classification or identification to it from the start.
Unlabeled data would be the tub of old photographs while labeled data might be the same tub of photographs but with ‘Christmas 1982’, ‘Birthday 1983’, ‘Joe and Kelly’ etc. scrawled in black felt tip on the back of each one. (Here’s another good answer to the difference between labeled and unlabeled data.)
Why is this important? Let’s return to Jeff Dean (who is a very important figure in my view) to tell us.
You’re always going to have 100x, 1000x as much unlabeled data as labeled data, so being able to use that is going to be really important.
The difference between supervised learning and unsupervised learning is similar. Supervised learning means that the model is looking to fit things into a pre-conceived classification. Look at these photos and tell me which of them are cats. You already know what you want it to find. Unsupervised learning on the other hand lets the model find it’s own classifications.
If I have it right, supervised learning has a training set of labeled data where a unsupervised learning has no initial training set. All of this is wrapped up in the fascinating idea of neural networks.
The different models for learning via neural nets, and their variations and refinements, are myriad. Moreover, researchers do not always clearly understand why certain techniques work better than others. Still, the models share at least one thing: the more data available for training, the better the methods work.
The emphasis here is mine because I think it’s extremely relevant. Caffeine and Hummingbird allow Google to both use more data and to process that data quickly. Maybe Hummingbird is the ability to deploy additional layers of unsupervised learning across a massive corpus of documents?
And that cat reference isn’t just because I like LOLcats. A team at Google (including Jeff Dean) was able to use unlabeled, unsupervised learning to identify cats (among other things) in YouTube thumbnails (PDF).
So what does this all have to do with Hummingbird? Quite a bit if I’m connecting the dots the right way. Once again I’ll refer back the Jeff Dean interview (which I seem to get something new out of each time I read it).
We’re also collaborating with a bunch of different groups within Google to see how we can solve their problems, both in the short and medium term, and then also thinking about where we want to be four years, five years down the road. It’s nice to have short-term to medium-term things that we can apply and see real change in our products, but also have longer-term, five to 10 year goals that we’re working toward.
Remember at the end of Back to The Future when Doc shows up and implores Marty to come to the future with him? The flux capacitor used to need plutonium to reach critical mass but this time all it takes is some banana peels and the dregs from some Miller Beer in a Mr. Fusion home reactor.
So not only is Hummingbird a hybrid engine but it’s hooked up to something that can turn relatively little into a whole lot.
Quantum Computing
So lets take this a little bit further and look at Google’s interest in quantum computing. Back in 2009 Hartmut Neven was talking about the use of quantum algorithms in machine learning.
Over the past three years a team at Google has studied how problems such as recognizing an object in an image or learning to make an optimal decision based on example data can be made amenable to solution by quantum algorithms. The algorithms we employ are the quantum adiabatic algorithms discovered by Edward Farhi and collaborators at MIT. These algorithms promise to find higher quality solutions for optimization problems than obtainable with classical solvers.
This seems to have yielded positive results because in May 2013 Google upped the ante and entered into a quantum computer partnership with NASA. As part of that announcement we got some insight into Google’s use of quantum algorithms.
We’ve already developed some quantum machine learning algorithms. One produces very compact, efficient recognizers — very useful when you’re short on power, as on a mobile device. Another can handle highly polluted training data, where a high percentage of the examples are mislabeled, as they often are in the real world. And we’ve learned some useful principles: e.g., you get the best results not with pure quantum computing, but by mixing quantum and classical computing.
A highly polluted set of training data where many examples are mislabeled? Makes you wonder what that might be doesn’t it? Link graph analysis perhaps?
Are quantum algorithms part of Hummingbird? I can’t be certain. But I believe that Hummingbird lays the groundwork for these types of leaps in optimization.
What About Conversational Search?

There’s also a lot of talk about conversational search (pun intended). I think many are conflating Hummingbird with the gains in conversational search. Mind you, the basis of voice and conversational search is still machine learning. But Google’s focus on conversational search is largely a nod to the future.
We believe that voice will be fundamental to building future interactions with the new devices that we are seeing.
And the first area where they’ve made advances is the ability to resolve pronouns in query chains.
Google understood my context. It understood what I was talking about. Just as if I was having a conversation with you and talking about the Eiffel Tower, I wouldn’t have to keep repeating it over and over again.
Does this mean that Google can resolve pronouns within documents? They’re getting better at that (there a huge corpus of research actually) but I doubt it’s to the level we see in this distinct search microcosm.
Conversational search has a different syntax and demands a slightly different language model to better return results. So Google’s betting that conversational search will be the dominant method of searching and is adapting as necessary.
What Does Hummingbird Do?

This seems to be the real conundrum when people look at Hummingbird. If it affects 90% of searches worldwide why didn’t we notice the change?
Hummingbird makes results even more useful and relevant, especially when you ask Google long, complex questions.
That’s what Amit says of Hummingbird and I think this makes sense and can map back to the idea of synonyms (which are still quite powerful). But now, instead of looking at a long query and looking at word synonyms Google could also be applying entity synonyms.
Understanding the meaning of the query might be more important than the specific words used in the query. It reminds me a bit of Aardvark which was purchased by Google in February 2010.
Aardvark analyzes questions to determine what they’re about and then matches each question to people with relevant knowledge and interests to give you an answer quickly.
I remember using the service and seeing how it would interpret messy questions and then deliver a ‘scrubbed’ question to potential candidates for answering. There was a good deal of technology at work in the background and I feel like I’m seeing it magnified with Hummingbird.
And it resonates with what Jeff Dean has to say about analyzing sentences.
I think we will have a much better handle on text understanding, as well. You see the very slightest glimmer of that in word vectors, and what we’d like to get to where we have higher level understanding than just words. If we could get to the point where we understand sentences, that will really be quite powerful. So if two sentences mean the same thing but are written very differently, and we are able to tell that, that would be really powerful. Because then you do sort of understand the text at some level because you can paraphrase it.
My take is that 90% of the searches were affected because documents that appear in those results were re-scored or refined through the addition of entity data and the application of machine learning across a larger data set.
It’s not that those results have changed but that they have the potential to change based on the new infrastructure in place.
Hummingbird Response

How should you respond to Hummingbird? Honestly, there’s not a whole lot to do in many ways if you’ve been practicing a certain type of SEO.
Despite the advice to simply write like no one’s watching, you should make sure you’re writing is tight and is using subjects that can be identified by people and search engines. “It is a beautiful thing” won’t do as well as “Picasso’s Lobster and Cat is a beautiful painting”.
You’ll want to make your content easy to read and remember, link out to relevant and respected sources, build your authority by demonstrating your subject expertise, engage in the type of social outreach that produces true fans and conduct more traditional marketing and brand building efforts.
TL;DR
Hummingbird is an infrastructure change that allows Google to take advantage of additional sources of data, such as entities, as well as leverage new deep learning models that increase the precision of current algorithms. The first application of Hummingbird was the refinement of Google’s document topic modeling, which is vital to delivering relevant search results.