There’s been a tremendous amount of chatter recently about rich snippets vanishing from Google search results, whether it’s Amazon losing their review aggregate snippets or a wholesale reduction in video snippets.
What we’re really talking about are changes to the rich snippets algorithm.

That’s right, we need to go deeper. There’s an algorithm within the algorithm.
Here’s what I know about the rich snippets algorithm based on observation and conjecture as well as statements from Google representatives. I’ll also sketch out some theories on how Google might be replacing many rich snippets with Knowledge Graph panels and carousels.
Rich Snippets History

Lets start at the beginning. Rich snippets were first introduced by Google on May 12, 2009. The strange thing is Google was the last search engine to embrace rich snippets.
For a long time Google didn’t want to employ a feature that would be naturally biased toward sites with greater development resources. In short, Google wanted to keep a level playing field. You still see some of this mentality in the Data Highlighter feature in Google Webmaster Tools.
But once they started down the rich snippets road Google all-in, launching Schema.org on June 2, 2011. Sure it’s a joint venture between search engines but lets be real, the main author here is Google.
Not Your Ordinary Result
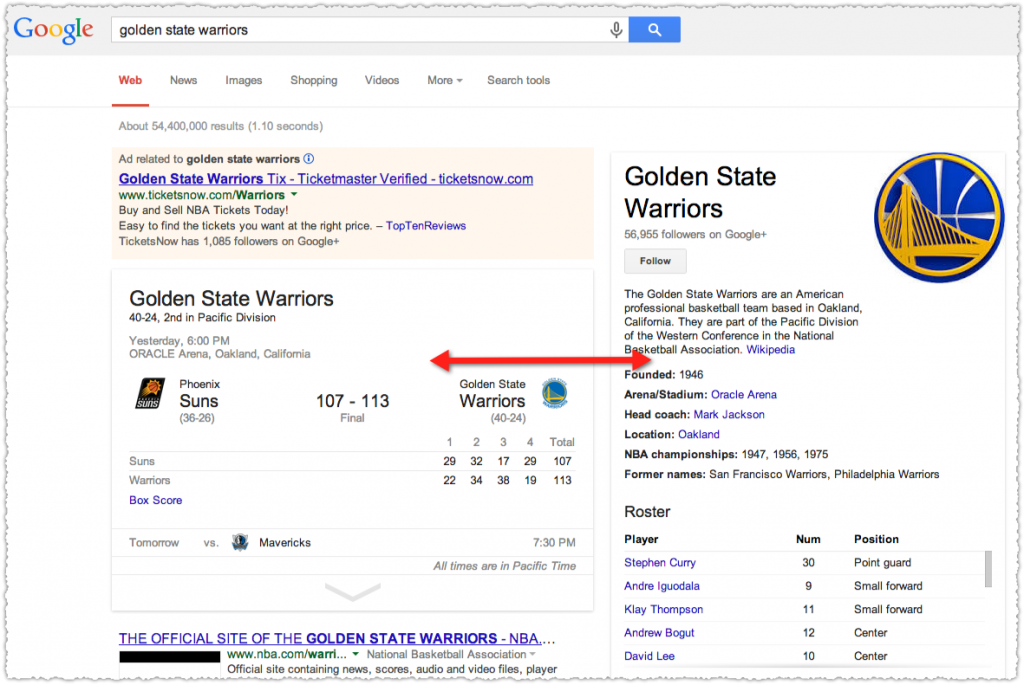
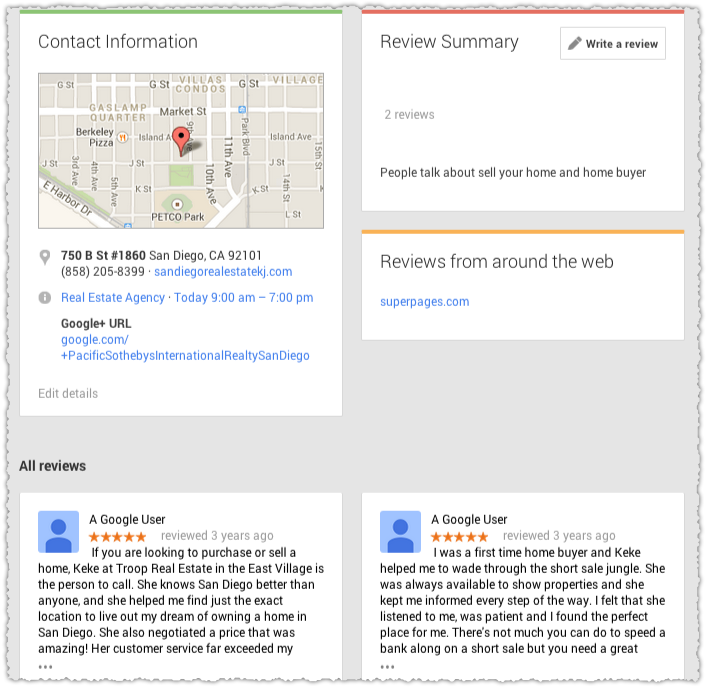
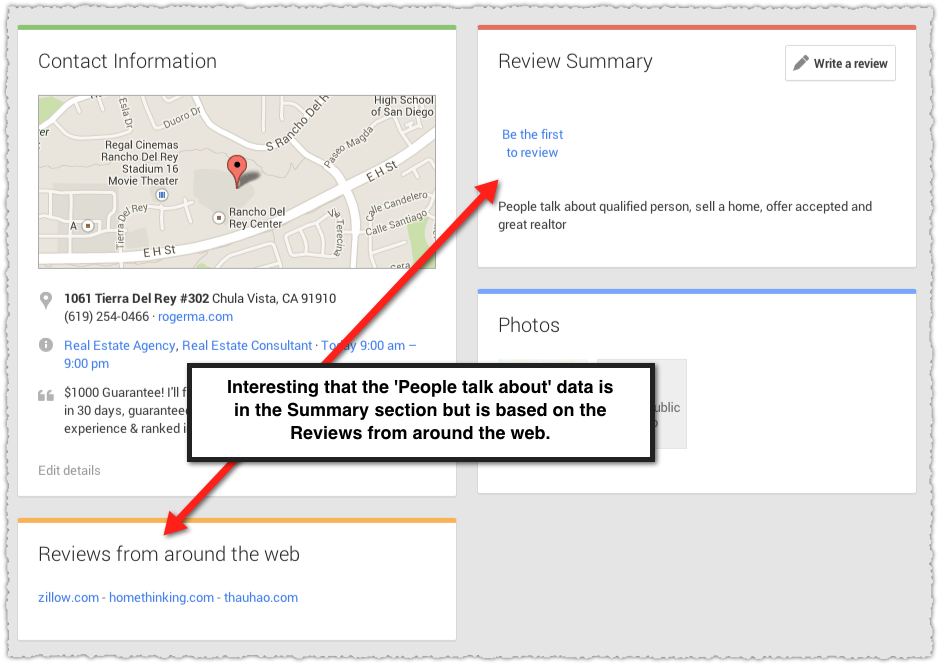
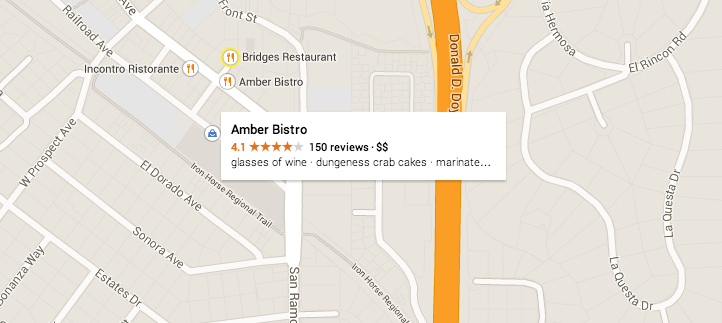
Rich snippets are fancy results or results on steroids. They usually contain a visual element such as stars or a thumbnail image.

Whether they’re stars, additional links, thumbnail images or video captures, these results stand out from the crowd. As such, they draw both the eye and clicks.
Whitelist Days Of Yore
In the old days (circa 2010) I was working with PowerReviews and, by proxy, a number of eCommerce companies who were chomping at the bit to get the review aggregate snippet on their results.
Those stars were extremely powerful in those early days. Anything shiny and new will have that initial heightened response. The review rich snippet is still valuable but less so now that the novelty has worn off and there are multiple review rich snippets per result.
At the time, it was all about interfacing with the ‘rich snippets team’ and getting them to ‘turn on’ your snippets. As rich snippets grew in popularity and expanded to new types this non-algorithmic approach was untenable and simply … un-Googly.
Rich Snippets Algorithm
It shouldn’t be a surprise that there’s a rich snippets algorithm. Google states it clearly in their rich snippets guidelines.

For a long time this algorithm was rather basic and disconnected from other search quality signals. It wasn’t until the release of Panda 4.0 that Google integrated search quality signals with the rich snippets algorithm.
That’s not entirely true. Prior to that they’d done something because the review aggregate snippets for one of my clients just up and vanished one day.
I scratched my head and for months in early 2014 had the team tweak the code and fix every stray microdata error or potential conflict that could be responsible for what I assumed was some markup confusion. But nothing worked. In frustration I gave up, cursed Google, and put it on the back burner.
When Panda 4.0 was released this client’s review aggregate snippets magically returned along with a huge boost in rank. At the same time, I had another client hit by Panda 4.0 who lost their snippets and saw the Panda-typical decline in rank and traffic. So it became crystal clear.
Site quality is now part of the rich snippets algorithm.
From Google’s perspective it makes perfect sense. If the search quality team believes the site isn’t very good then why would Google render a rich snippet that would draw more attention and clicks to results from that site?
What that means is Panda Jail produces a double whammy of rank reduction and rich snippet suppression.
Validating Rich Snippet Suppression
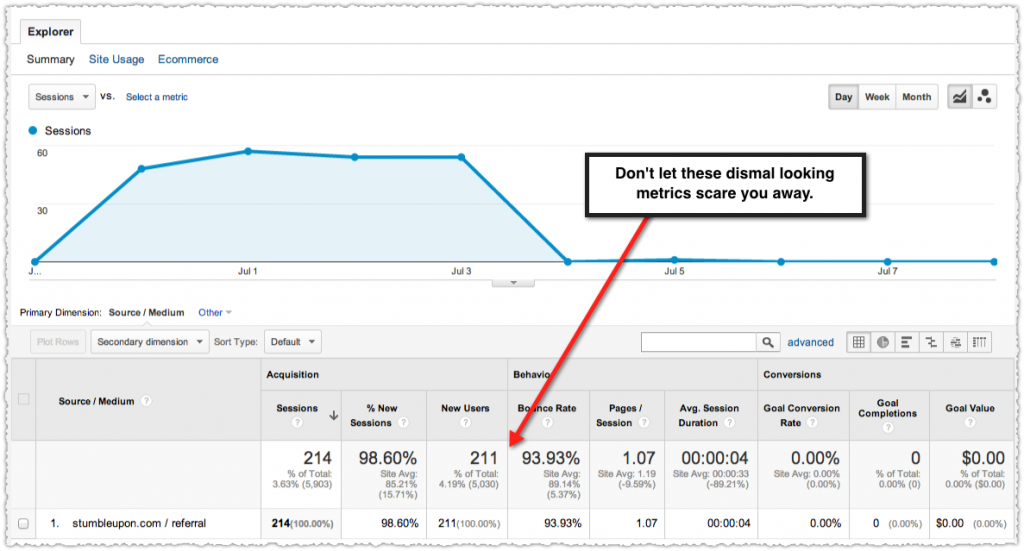
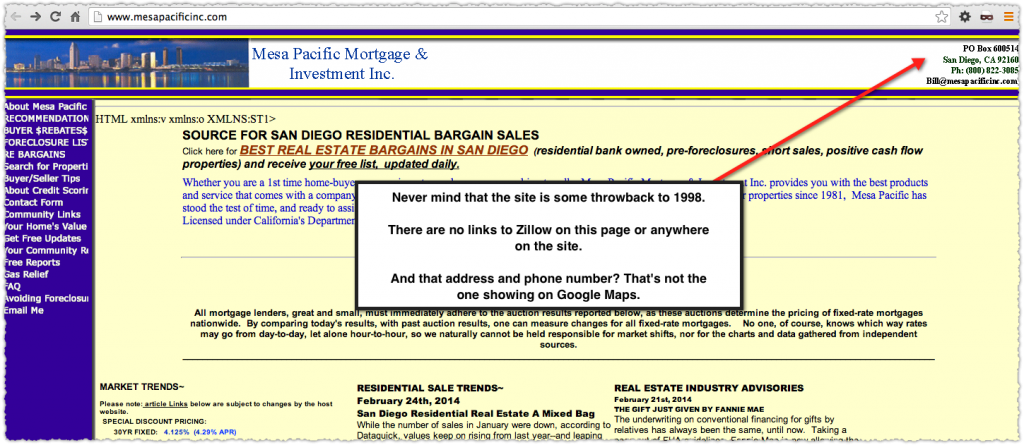
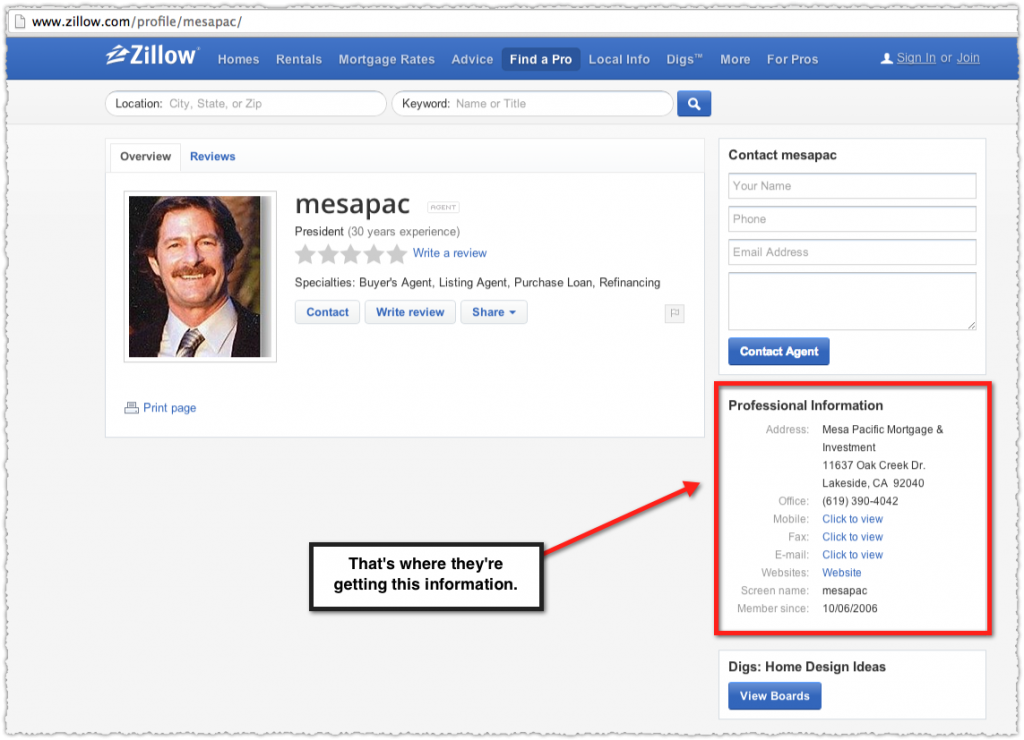
You can validate the rich snippets suppression by using the site: operator for a query that should be showing rich snippets but isn’t. Here is a search for ‘dr waldo frankenstein’.
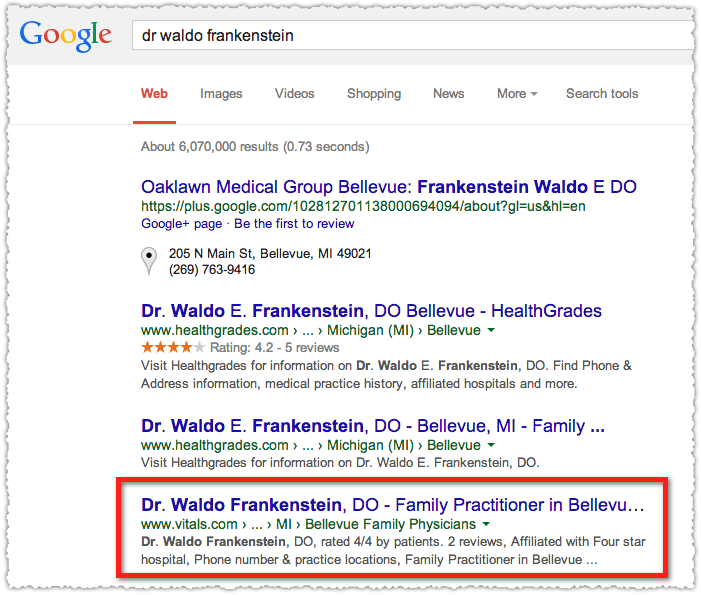
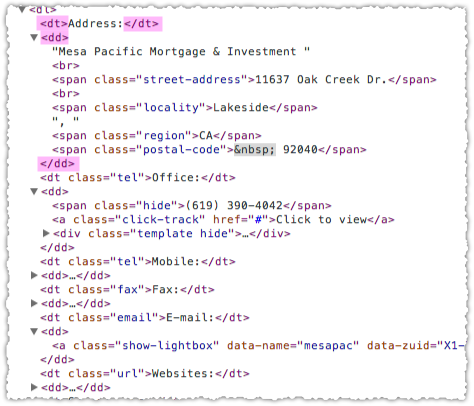
The vitals.com result does not have a rich snippet. Using my structured data testing tool bookmarklet I can tell the page does have the review aggregate markup in place. So then we just perform the same query with a site:vitals.com prefix.
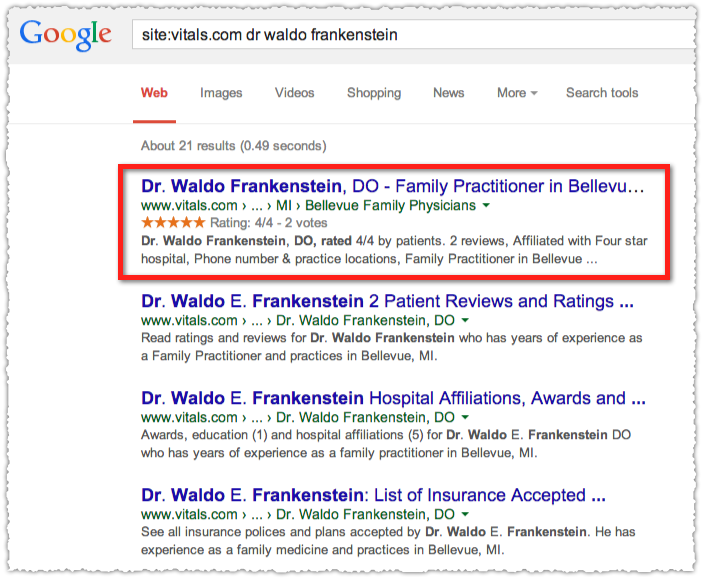
That’s the same page but this time the review aggregate rich snippet shows up. This is a clear case where Google is intentionally suppressing the rich snippet in normal search results.
Rich Snippets Relevance and Expertise
All of this doesn’t quite explain the big reduction in video snippets though does it? Many of the sites that lost video snippets weren’t Panda victims nor would you think they’d fall into some sort of non-authoritative bucket.
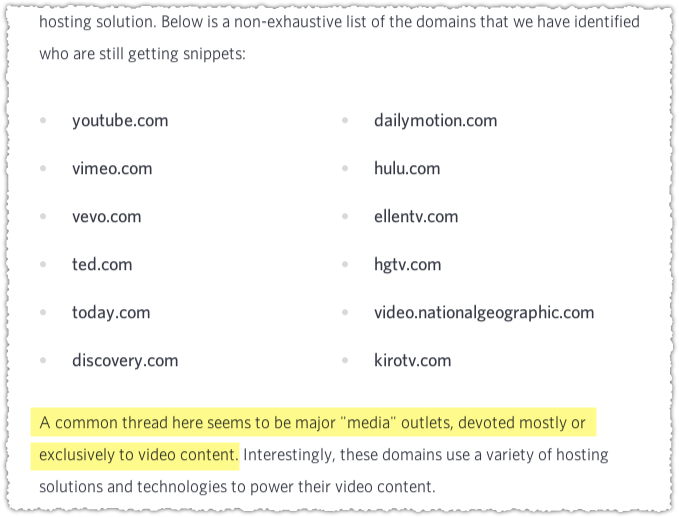
Casey Henry nails it in seeing the pattern. Those sites that are dedicated to video continue to get the video snippet. The algorithm seems to be looking for ‘topical’ expertise when rendering snippets. I don’t think Google wanted any ol’ site ‘hacking’ search results with a video result. (Yes, there was a cottage industry of folks doing this.)
I’ve seen this same ‘expertise’ issue occur on larger general interest sites. They may have received a recipe snippet before, but the new rich snippets algorithm decides not to render it because the site doesn’t have a focus or an expertise in recipes.
This expertise signal is a bit tough to pin down since there are other factors, such as overall site quality, involved. But it seems logical that Google is moving toward rendering snippets only when that site and snippet deliver relevance and expertise.
NASCAR SERPs?

The number of rich snippets per query might be a factor as well. Or if it isn’t, I think it will be soon. However, it is super dependent on the query.
For instance, search for ‘funny cat videos‘ and you get 8 video rich snippets, 7 of them from YouTube and one of them from Animal Planet. This makes a bit of sense since the query syntax makes it clear they’re looking for videos.
Sadly, a search for ‘funny cat‘ actually yields 10 video snippets, all from YouTube. I’ll give Google a pass with the query ‘funny cat’ since my guess is the overwhelming modifier is, in fact, ‘videos’.
So lets try the difference between ‘ombre hair’ and ‘ombre hair video’.
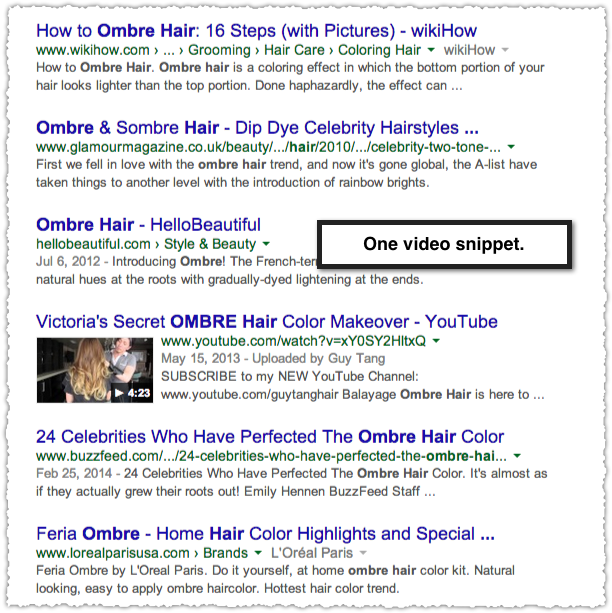
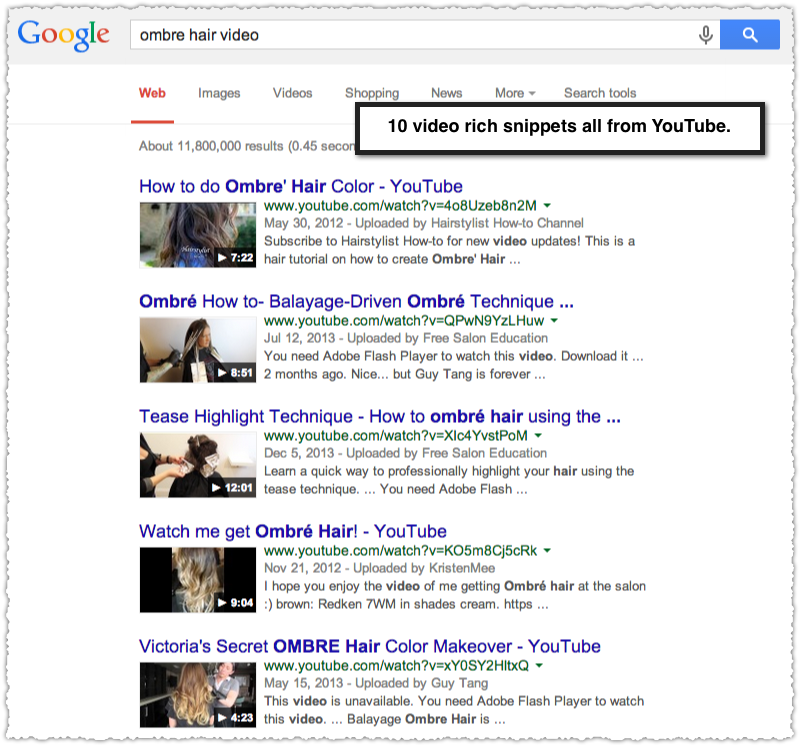
Sure enough you get just one video snippet with ‘ombre hair’ and a full 10 video snippets with ‘ombre hair video’. The only problem? They’re all from YouTube. In fact the first 15 are YouTube video snippets.
Look for a tweak to the rich snippets algorithm to dial back the YouTube host crowding issue. Even if YouTube is the most popular video destination it’s a public relations disaster to have it dominate to such an extent.
Similarly when you use ‘recipe’ in the query you get more recipe rich snippets. I’ve noticed that Google regularly removes the universal image result when you append the modifier ‘recipe’ to any ‘dish’ query.
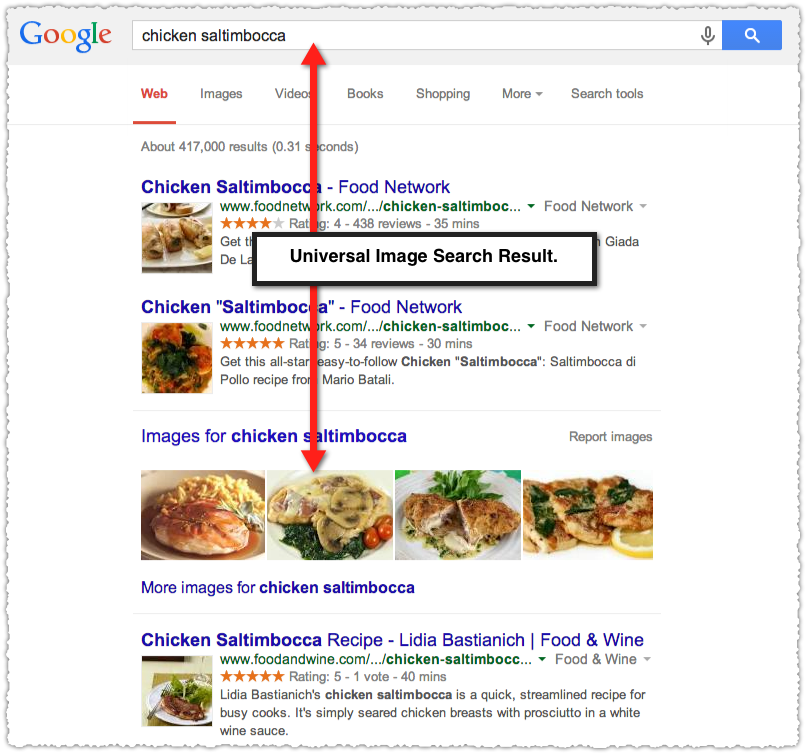
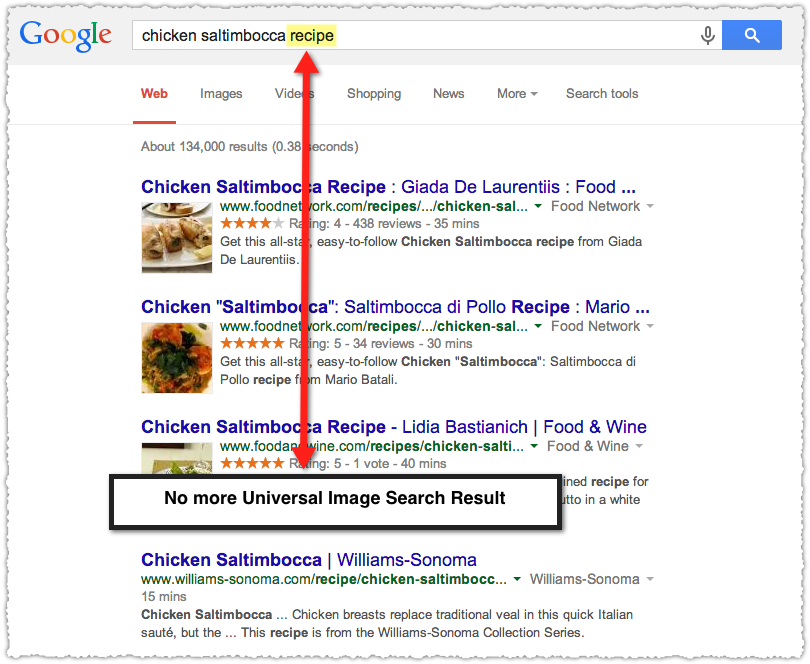
This makes sense. When you use the term ‘recipe’ in your query you’re looking for, well, recipes.
Query syntax and intent have an increasing influence on search results design and configuration.
But there are times when site quality and relevance aren’t in question and the only reason the rich snippet isn’t rendering seems to be that there are already a number of rich snippets in the results.
The problem is I can’t locate a good example of this signal at the time of writing. I had some examples but now they’re not working as advertised. So am I just reaching here? Maybe, but I don’t think so.
Too Much Of A Good Thing

The concept makes sense and there are recent precedents to support it. Google tweaked the number of authorship images showing up prior to removing them completely. No one wanted to see face after face in their results and certainly not the same face multiple times.
User experience consistency was the reason given for the elimination of authorship images. There’s a prominent mention about cleaning up ‘the visual design of search results’.
In a Google+ Google Webmaster Central hangout shortly afterwards John Mueller (Webmaster Trends Analyst but really so much more than that) seemed to go a bit further and speak to the user experience decisions Google makes with regards to rich snippets.
So for example, if we were to show the authorship photo for all search results, then maybe that would be too much for the majority of the users, even if we had that information. So that’s something where, in the beginning when only very few sites implemented authorship, maybe it made sense to show them all. Maybe now that a lot of sites are implementing authorship, maybe it makes sense to reduce that, or maybe to switch over to the text-based annotation.
Now John is talking about authorship snippets specifically but it seems like this would apply to any visual element in search results. And this isn’t the first time Google’s dialed back images based on user testing and research. The first social annotations Google applied (those small faces under results) weren’t well received by users (pdf) and quickly disappeared.
When everything screams to be looked at, you look at nothing.
Mark Traphagen does a bang-up job teasing it out in his authorship post on Moz and was extremely helpful in pointing me at specific comments. Prior to full removal Google developed a sort of tiered class system for authorship snippets detailed by Mark in his Great Google Authorship Kidnapping piece on Stone Temple.
The first class received the thumbnail image and the second class only got a byline. This might have simply been about site quality and not about the total number of snippets in a result.
Yet coupled with the comments from John after the fact, it makes me wonder if it also served to test visual snippet density.
Choosing Favorites Is Hard
I think Google is concerned about making the results too cluttered. From the start Google has maintained a type of less is more approach. Just look at their home page.
So at some point it makes sense to me that only a certain number snippets would render per query result, varying by the topic and query syntax. But which results get the rich snippet would make a humongous difference and become a bone of contention.
Do the rich just get richer? Or does the one site that has more topical expertise get the snippet over a larger national brand?
Google hasn’t had to deal with this problem in large part because the adoption of markup has been slow. But as more sites add structured data, how does Google deal with search results with multiple visual elements?
Maybe they don’t.
Knowledge Panels Eat Snippets
As I investigated this topic and went down the rabbit hole I came across an interesting 2010 paper titled How Google is using Linked Data Today and Vision For Tomorrow (pdf). The focus of the paper was on using linked data in rich snippets.
First they looked at how much structured data was currently being used.
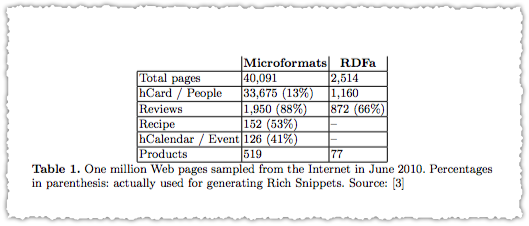
The result was a paltry 4.3% using any type of structured data and only 0.7% being used to generate rich snippets. A 2014 report from Searchmetrics indicates that the adoption hasn’t grown much in the intervening time.
But what’s more intriguing are the proposed ‘extended’ rich snippet examples.
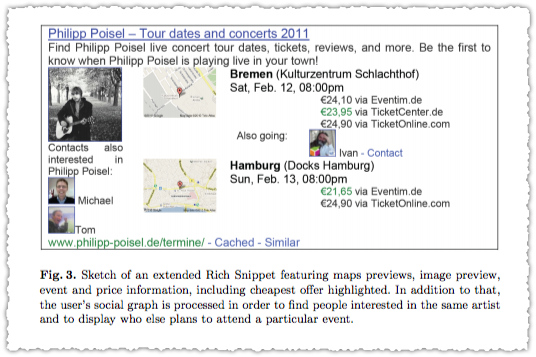
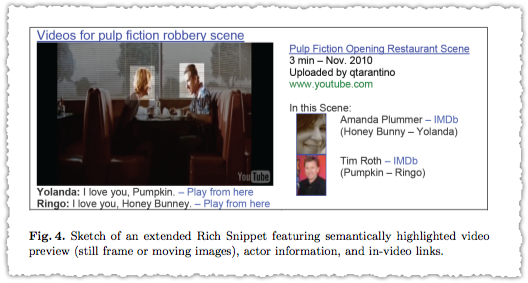
What I can’t help think looking at these is how closely they map to new Knowledge Graph panels. It’s a bit like that old Reese’s Peanut Butter commercial. But here’s the thing. If this was a video from someone other than YouTube and it included links to another site’s content I think the first site’s head would explode.
“How dare Google put links to other sites in my result!”
You can’t think that someone like, say, Last.fm would be keen to have links to Wikipedia or ticketing sites in their result for an artist query. So moving all of that to a centralized location like the Knowledge Panel is almost a necessity.
Google Killed The Radio Star
I’m using Last.fm as an example because from what I can tell Google has eliminated the music rich snippet. I can’t even get one to render using a site: operator, which leads me to believe its been deprecated. If you can get one to render please let me know.
I’m going to use the music snippet example Google provides on their About rich snippets and structured data page.
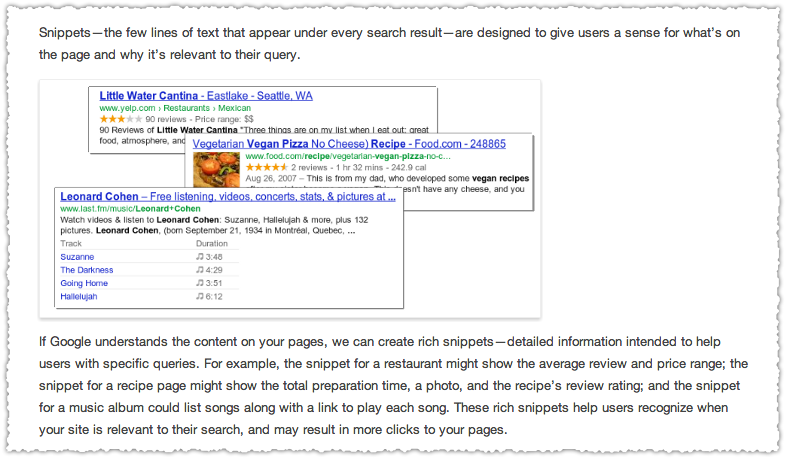
The music snippet here is for Leonard Cohen and from the bold sections of the result I’m assuming the query used to produce it was ‘Leonard Cohen’. Here’s what the Last.fm result looks like for that query today.
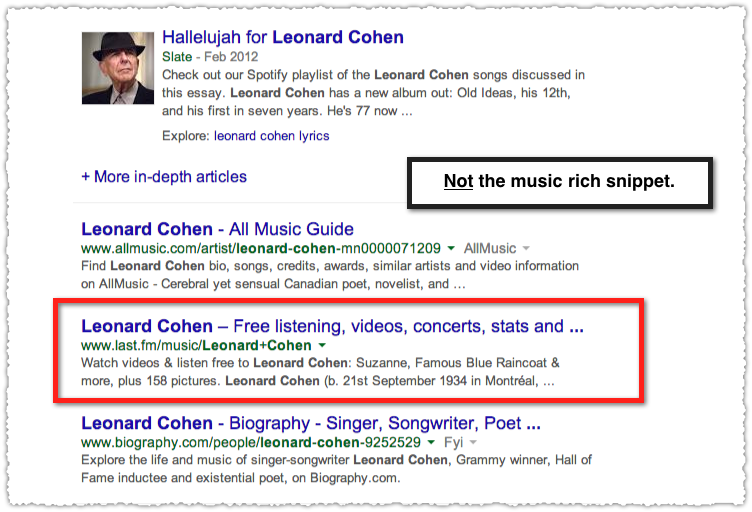
It’s the same URL but maybe Last.fm just screwed up their markup. I mean, it happens. So let’s run it through the structured data testing tool using my handy bookmarklet. (Seriously, it’ll shave hours of copy and paste work from your life!)
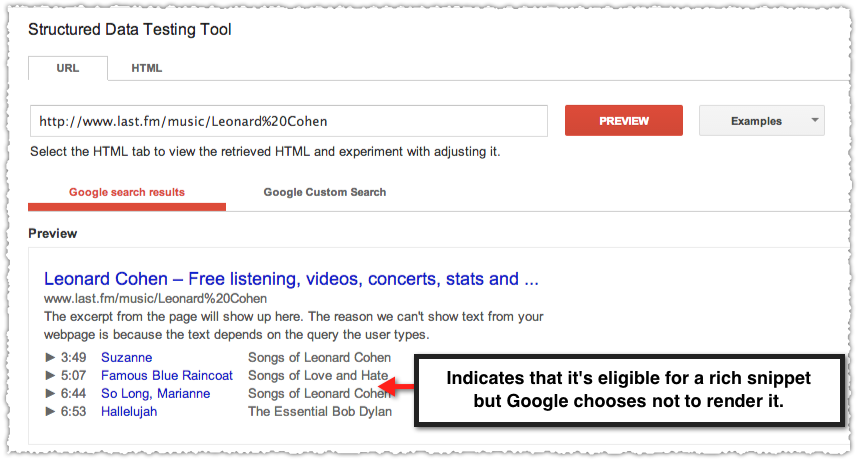
The markup is there. Google just chooses not to render it. Hey, those are the rules. And you can see why if you look at the Knowledge Panel in this search result.
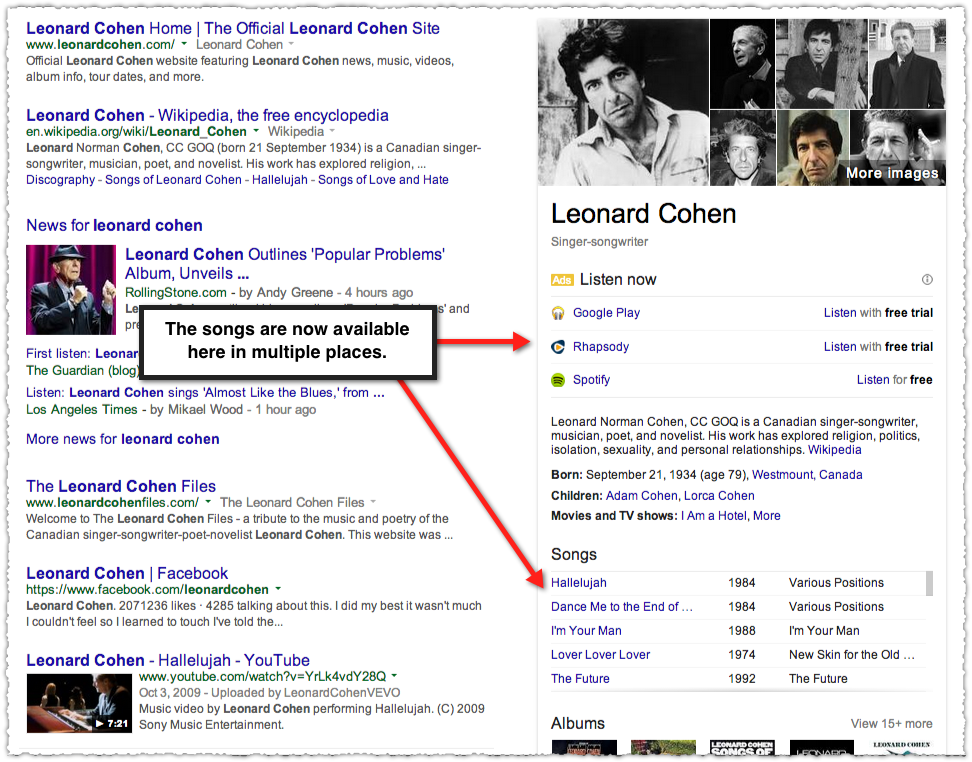
The Knowledge Panel has a ‘Songs’ section and a new ad unit to listen to music on multiple platforms. Click on any one of those songs and you get a full blown ‘songs’ carousel result.
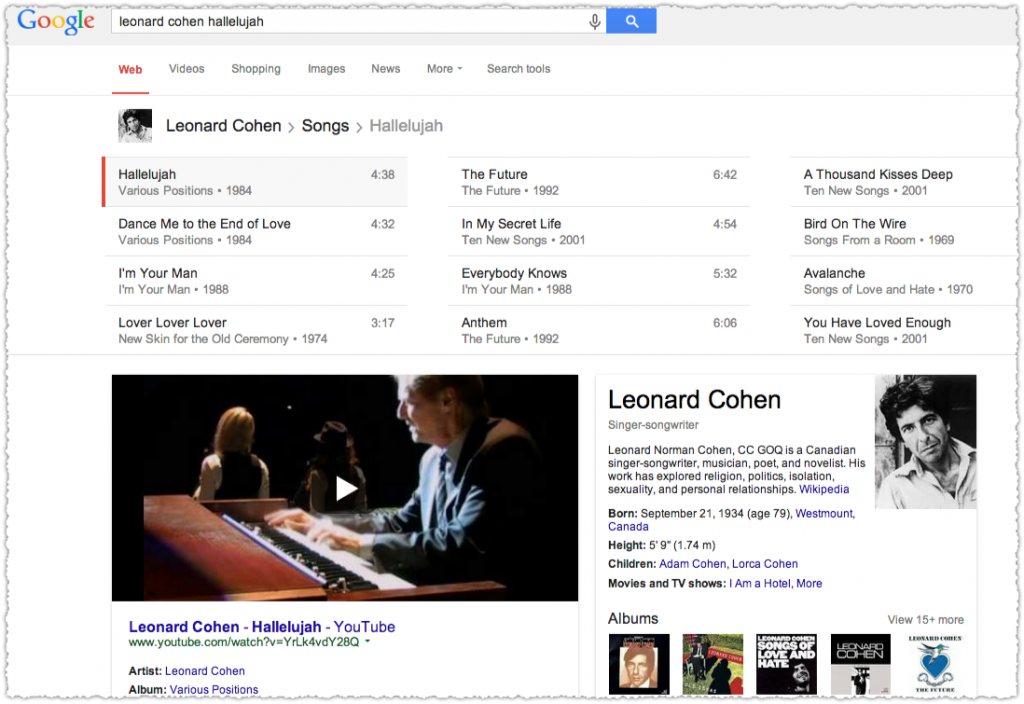
It’s pretty hard not to think this helps line Google’s pockets. It probably does.
The problem here is that sites don’t want competitive links in their Google search results and Google doesn’t want a long line of competing offers like some blinking-neon Las Vegas strip version of search results. Aggregating the various offers into one area of the page is a better user experience.
Knowledge Panels de-dupe, curate and aggregate intent for a better user experience.
The question then is how long until other types of rich snippets go the way of the Knowledge Panel?
Rich Snippets Ticket To Ride
Remember nearly 2,000 words ago when I mentioned Amazon had lost their review aggregate snippet. I took a screengrab of a specific instance of that about a week or so ago for my upcoming presentation on rich snippets.
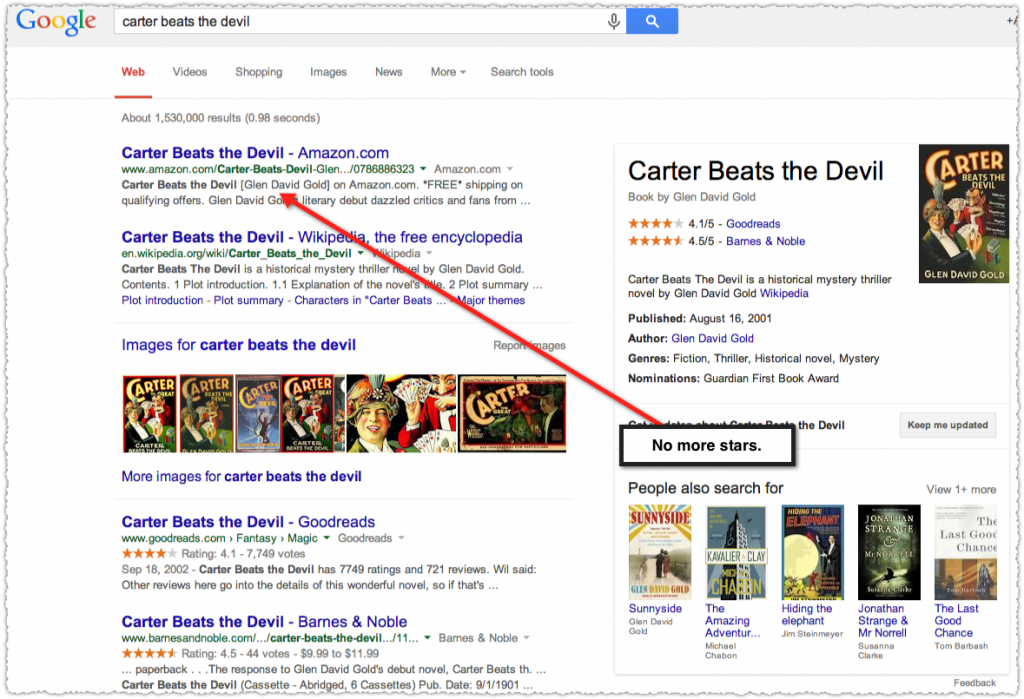
Instead of focusing on Amazon look at the two other rich snippets on the page from Goodreads and Barnes & Nobel and how they also appear in the Knowledge Panel. Now lets see how this same search looks today (August 19. 2014).
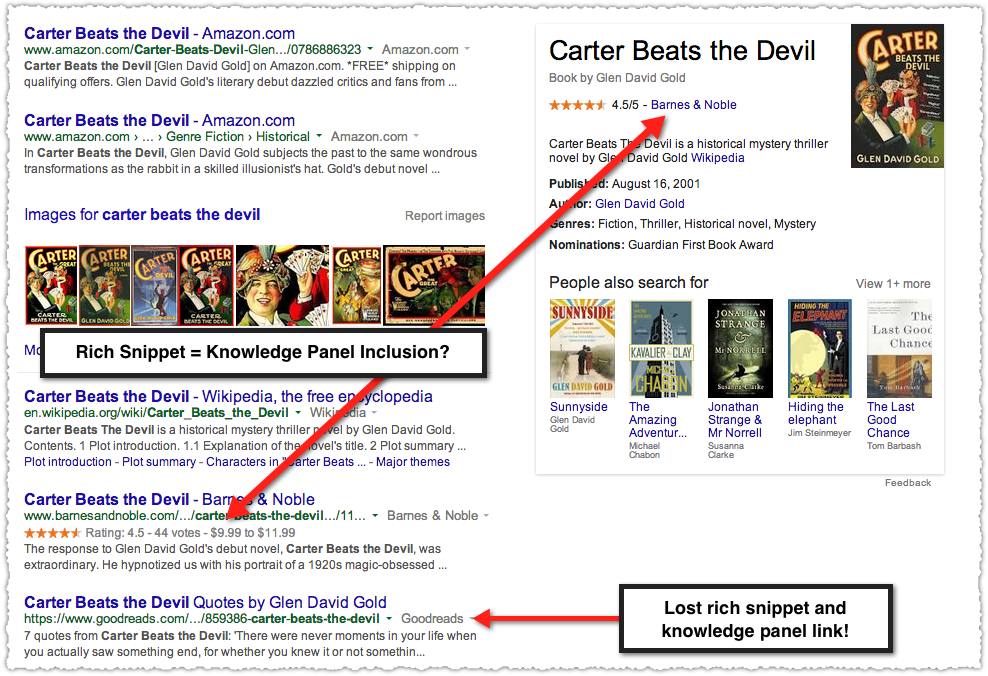
Goodreads lost their rich snippet and with it their link in the Knowledge Panel. The Goodreads result changed to one doesn’t have the review aggregate snippets markup. That’s a kick in the pants!
The review aggregate rich snippet gets you access to the Knowledge Panel unit. At least for the book vertical. And if you didn’t realize, that link to Barnes & Nobel is … a link to Barnes & Nobel. External folks!
Google doesn’t play favorites in ordering. The order in the Knowledge Panel is dictated by the order they appear in search results.
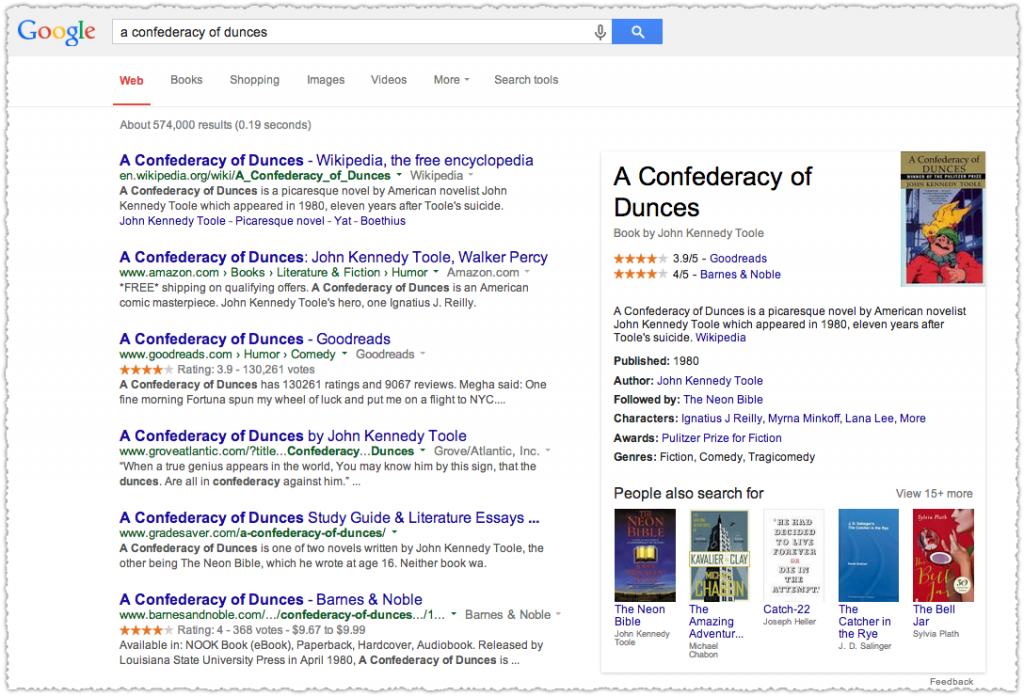
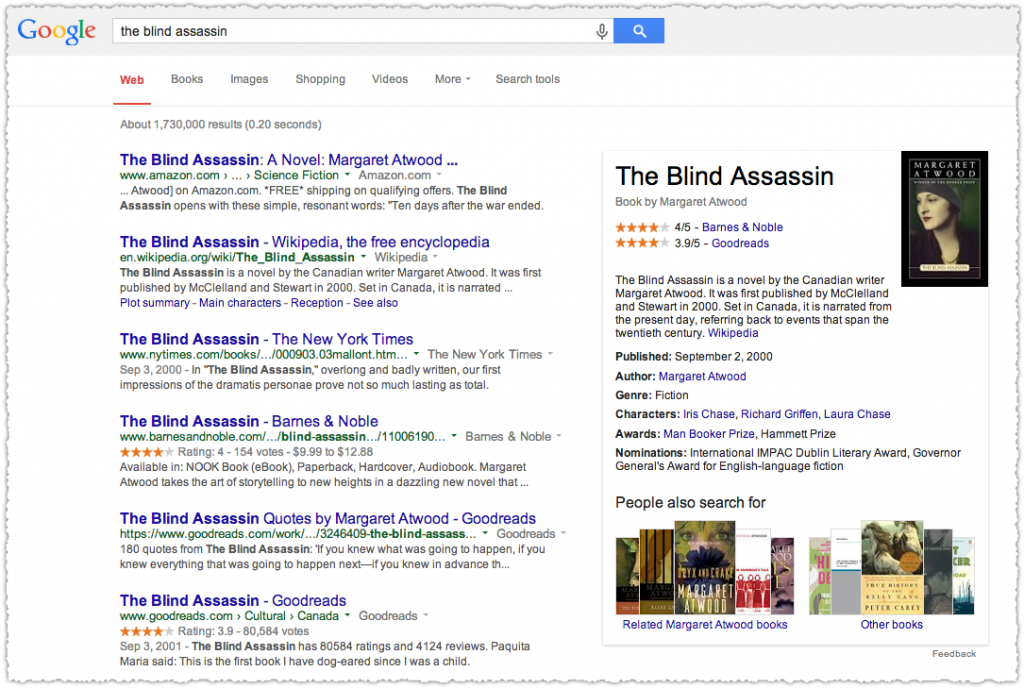
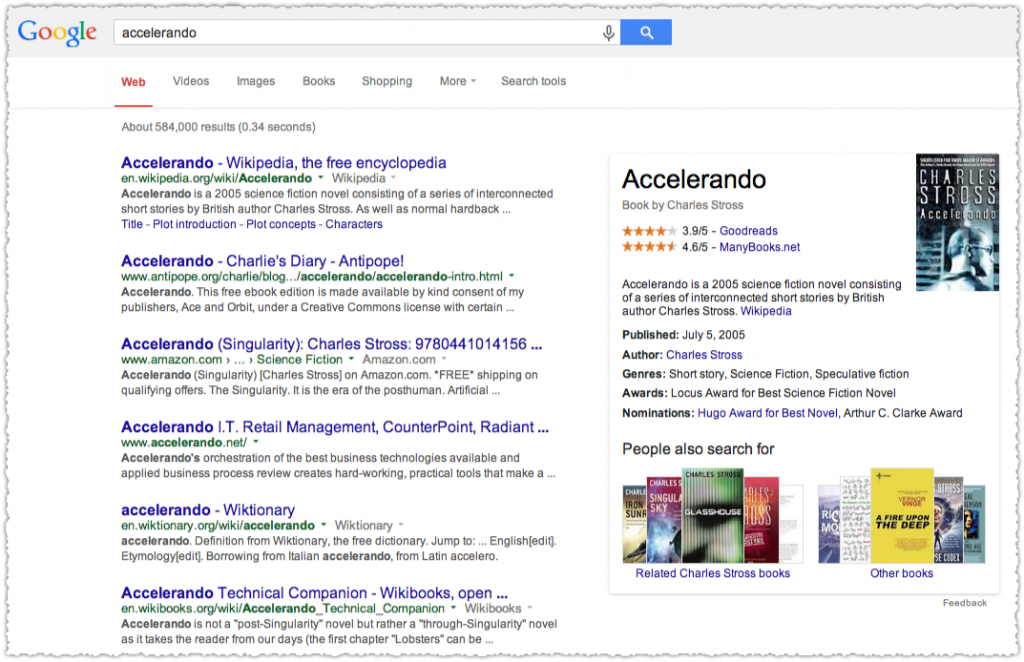
I included the last one here to show that other sites do qualify if they get their review aggregate rich snippet on the first page. ManyBooks is 8th on the ‘accelerando’ result.
But looking further down the road might Google simply remove all the rich snippets and aggregate them in the Knowledge Panel unit? Or maybe they’d only do that if the query was more specific and contained the word ‘review’. On a lark I tried ‘blind assassin reviews’.
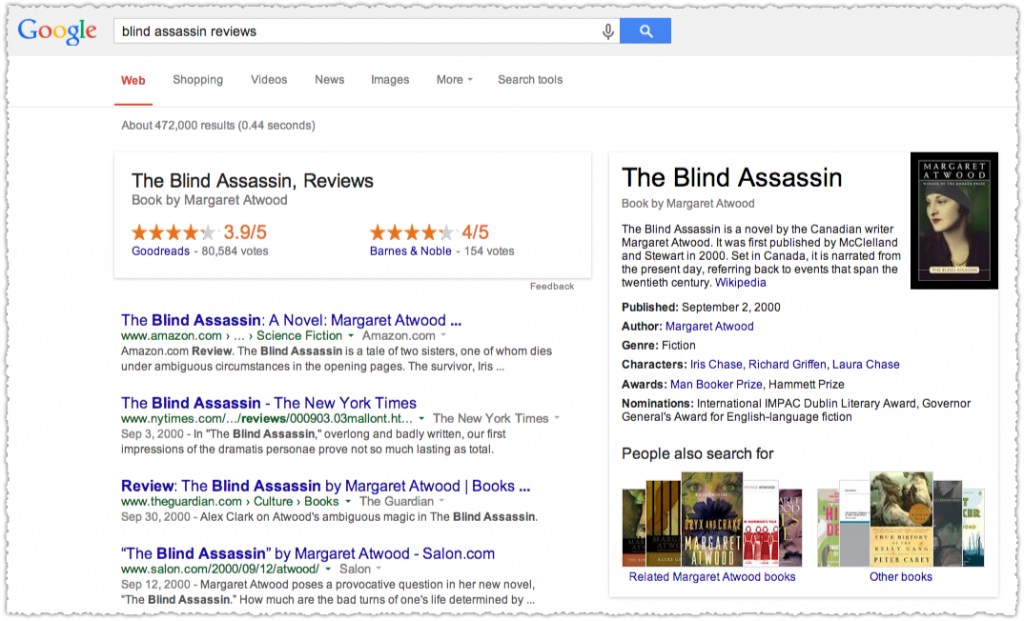
Will you look at that! Now both Goodreads and Barnes & Nobel have a starred result front and center. The rich snippets still show up in the individual results but it’s almost immaterial given this presentation. How about another?
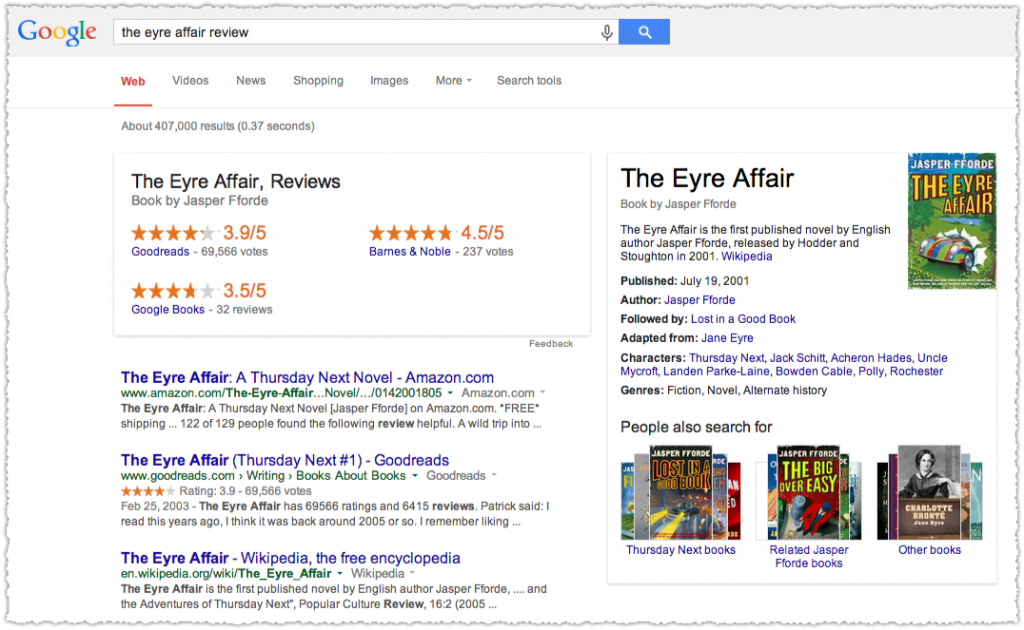
All three sites that have review aggregate rich snippets on page one also get this monstrous book reviews unit. I don’t know about you but it certainly feels like change is coming.
It’s easy with books because there is one representation of this ‘work’. The connection between the entity represented in the snippet and the Knowledge Panel is straight-forward.
But there is not just one funny cat video! However, could you decide that there is one representation for a ‘dish’? Might a new recipe Knowledge Panel include one big image and links to individual recipes from sites using the recipe rich snippet?
It doesn’t seem so far-fetched to me.
Rich Snippets Redux
Pulling myself out of the rabbit hole here’s what I’ve learned.
The Rich Snippets Algorithm Got Smarter
The new rich snippets algorithm clearly draws on site quality signals and may also be looking for topical expertise. Sites impacted by Panda will see both a reduction in rank and a suppression of any rich snippets.
Query Syntax Changes Search UX
Google is adopting new user interfaces for query syntax that indicate specific intent. The number of rich snippets and other visual elements change based on certain modifiers. Knowledge Panels in particular serve to de-dupe, curate and aggregate user intent.
Rich Snippets Are Linked To Knowledge Panels
In some instances rich snippets are being deprecated in lieu of Knowledge Panels (such as music) while other times rich snippets provide access to prime Knowledge Panel real estate.
So while the landscape continues to shift beneath our feet I believe implementing structured data is one of the smartest moves you can make given Google’s clear and continuing efforts around entities, the knowledge graph and Knowledge Panels.