A few months ago I offhandedly made a reference to KGO which stands for Knowledge Graph Optimization.
Now, I know what you’re thinking. We need another acronym like another hole in the head! But over the past year I feel like there are a set of tactics that can help you optimize your site’s connection to the Knowledge Graph. And that can yield material gains in search visibility.
The Knowledge Graph
Here’s a brief explanation from Google for those not familiar with the Knowledge Graph.
The Knowledge Graph enables you to search for things, people or places that Google knows about—landmarks, celebrities, cities, sports teams, buildings, geographical features, movies, celestial objects, works of art and more—and instantly get information that’s relevant to your query. This is a critical first step towards building the next generation of search, which taps into the collective intelligence of the web and understands the world a bit more like people do.
It’s about searching for things instead of strings. Or without the rhyming, it’s about entities instead of text.
Take the query ‘Golden State Warriors’. From a string stand point you’d be looking at the individual keywords which might be confusing. Now, Google got extremely good at understanding terms that were most frequently used together using bigrams and other methods so that this query would yield a result about the NBA basketball team.
But with the Knowledge Graph Google can instead identify ‘Golden State Warriors’ as an entity (a thing) that has a specific entry in the Knowledge Graph and return a much richer result.
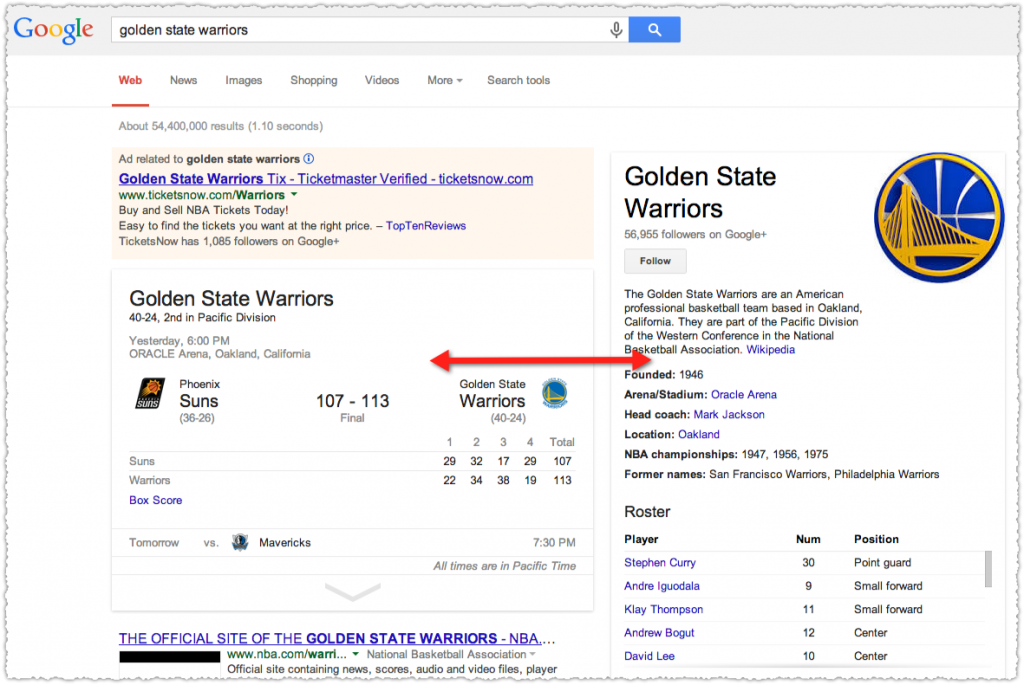
Pretty amazing stuff really. (Go Warriors!) Hummingbird was largely an infrastructure update that allowed Google to take advantage of burgeoning entity data. So we’re just getting started with the application of entities on search.
Entity Challenge

You need only look to the Entity Recognition and Disambiguation Challenge co-sponsored by Microsoft and Google to see the writing on the wall.
The objective of an Entity Recognition and Disambiguation (ERD) system is to recognize mentions of entities in a given text, disambiguate them, and map them to the entities in a given entity collection or knowledge base.
Can it be any more clear? Well, actually, it can.
The Challenge is composed of two parallel tracks. In the “long text” track, the challenge targets are pages crawled from the Web; these contain documents that are meant to be easily understood by humans. The “short text” track, on the other hand, consists of web search queries that are intended for a machine. As a result, the text is typically short and often lacks proper punctuation and capitalization.
Search engines are chomping at the bit to get better at extracting entities from documents and queries so they can return more relevant and valuable search results.
So …

But what exactly are we supposed to do? There has been little in the way of real rubber-meets-the-road content that describes how you might go about optimizing for this new world full of entities. One of the exceptions would be Aaron Bradley’s Semantic SEO post, though it mixes both theory and tactics.
Now, I love theory. That’s pretty clear from my writing. But today I want to talk more about tactics, about the actual stuff we can do as marketers to affect change in the Knowledge Graph.
Nouns

The first thing we can do is make sure we’re using the entity names in our writing. That ERD challenge above? Well, the systems they’re designing are looking to extract entities from text.
So if you’re not using the entity names – the nouns – in your writing then you’re going to make it vastly more difficult for search engines to identify and match entities. This does not mean you should engage in entity stuffing and mention every associated entity you can think of in your content.
Write clearly so that both humans and search engines know what the hell you’re talking about.
Connect

Stop hoarding authority and ‘link juice’ by not linking out to other sites. The connections between sites and pages are important and not just in a traditional PageRank formula.
I think of it this way. The entities that are contained on one page are transmitted to linked pages and vice versa.
Entities are meta information passed in links.
Structured Data

You can make the identification of entities easier for search engines by using schema.org markup along with some other forms of structured data. Not only will this ensure that the number of entities that are transmitted via links increase, it can often make connections to the Knowledge Graph with a very limited amount of data.
Google Maps Entity Hack
So, here’s the actual bit of discovery that I’ve been holding onto for six months and is the real impetus for this entire post. If you go to Google Maps and search for a branded term coupled with a geographic location you often get some very interesting results. Take ‘zillow san diego, ca‘ for instance.
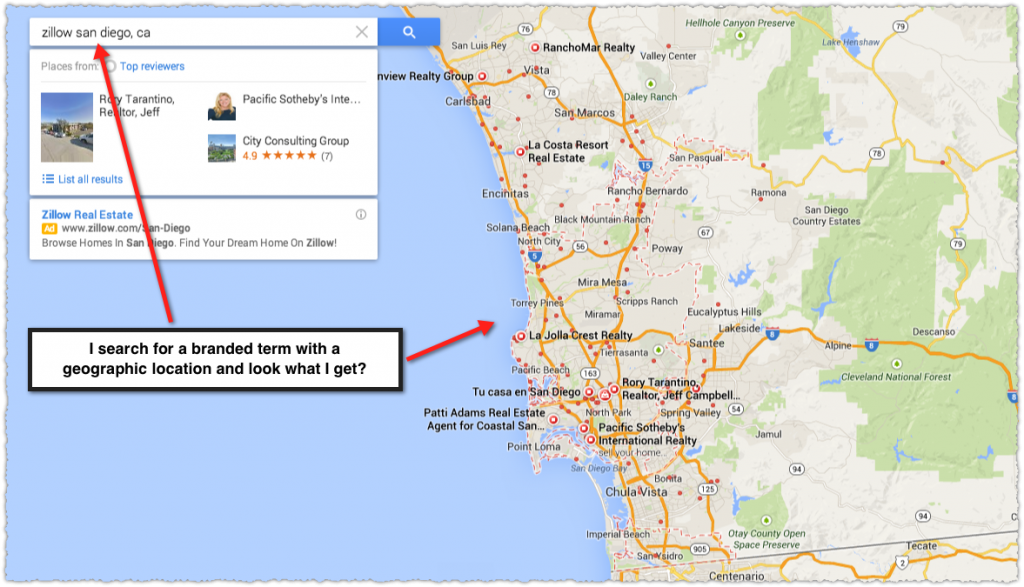
Look at all those results and red dots! I didn’t ask for realtors, mortgage brokers or appraisers in my query. I simply used the term Zillow in combination with a geography and got these very related and relevant results. They’re not simply looking for a Zillow office located in San Diego.
So, lets look at the details here to see what’s going on. I’ll take one of the red dots and investigate further.
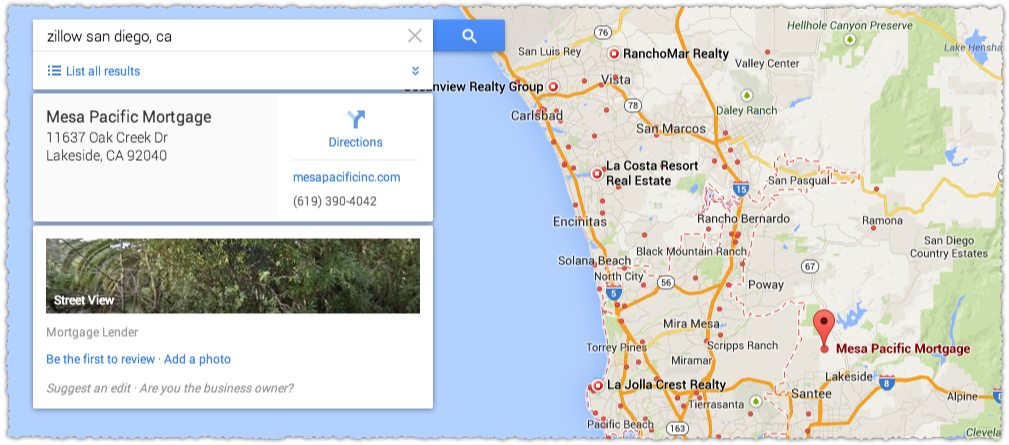
So why is this on the map results? First I go to the linked website.
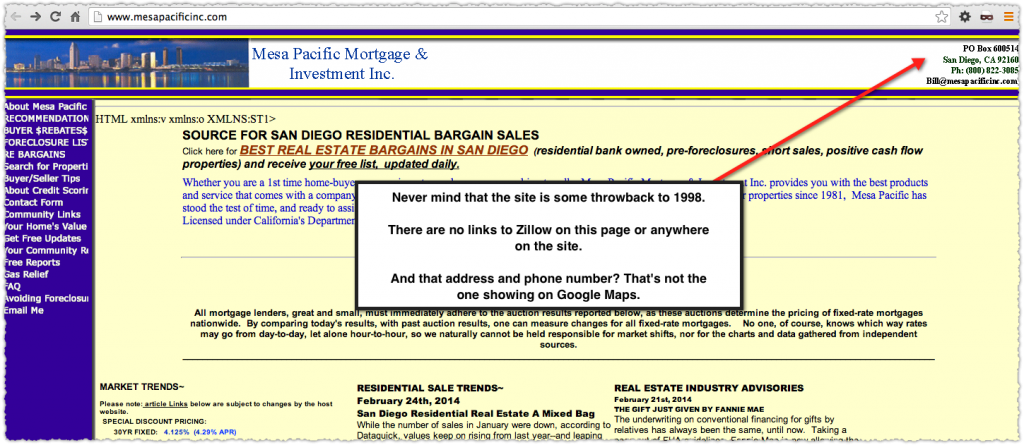
So, there are no links to Zillow anywhere on the site and the address and phone number here don’t match the one on Google Maps. But they are the ones listed on his Zillow Profile.
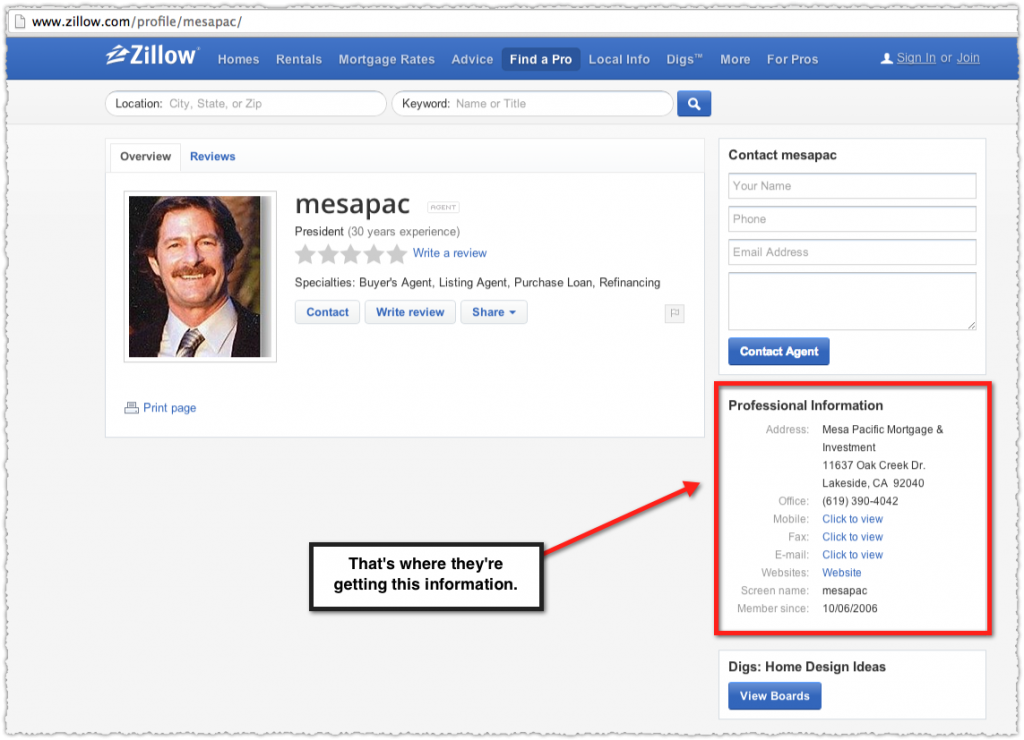
Now the link to the website closes the connection here so it’s not completely linkless, but I still find it pretty amazing. And this is without Zillow fully optimizing the markup. They declare the page as an organization.
![]()
But they don’t detail out the professional information with schema markup.
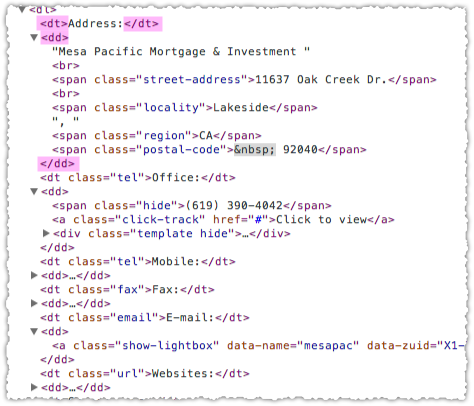
Instead they’re using some old(er) school definition list markup for list term and description. Combined with the organization scope it looks like Google can put 1 and 1 together.
Google+
In doing due diligence I found Mesa Pacific Mortgage also has a Google+ page which reinforces the right address and phone number. So the connection isn’t as startling as it might seem but it’s still intriguing.
And I have no idea in what order these things came into existence. It’s pretty clear the Zillow listing probably came first based on the 2006 Member Since date on his profile. Whether the Google+ Local page and associated map listing came directly as a result is unknown.
In fact, as you do more and more investigation as to what shows up on the map and what doesn’t it seems like a Google+ Local page is required. However, a fair amount of them have been created by Google. Obviously Google uses a multitude of sources to create these listing. If you can be one of those sources, all the better. But even if you’re not, connecting to these entities delivers value to all involved.
Lets look at another Google Maps result.
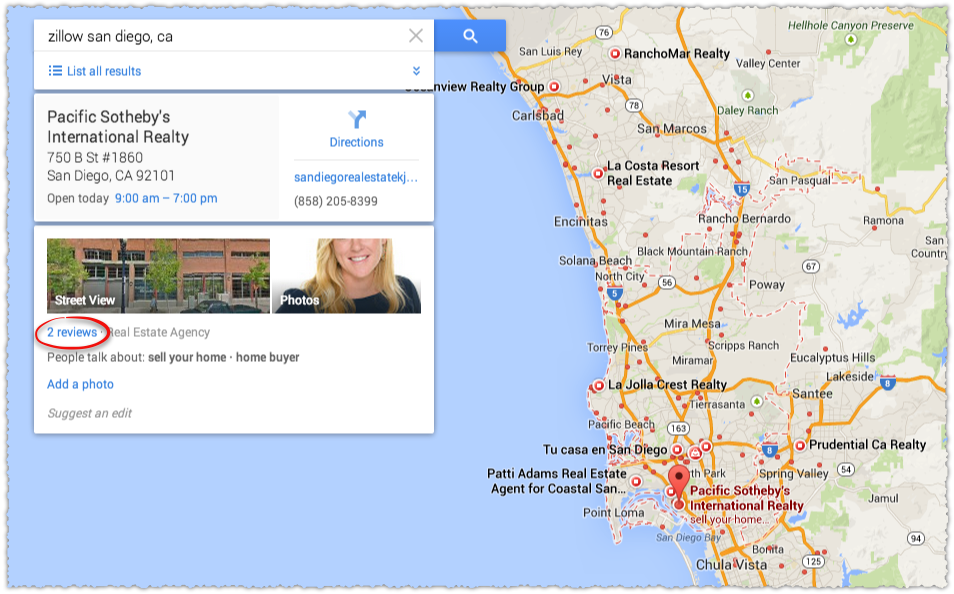
If you follow that reviews link you wind up on their Google+ page.
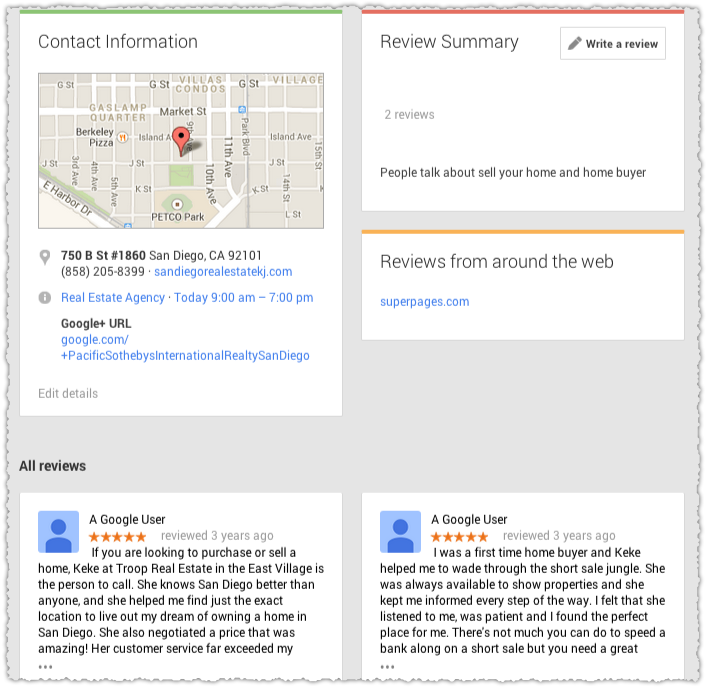
Odd that Google isn’t sucking in the reviews from Zillow, which would show a greater connection. Google+ Local Pages provide a vast database of entities for Google. And they rely on the data in Google+ more than that from other sources.
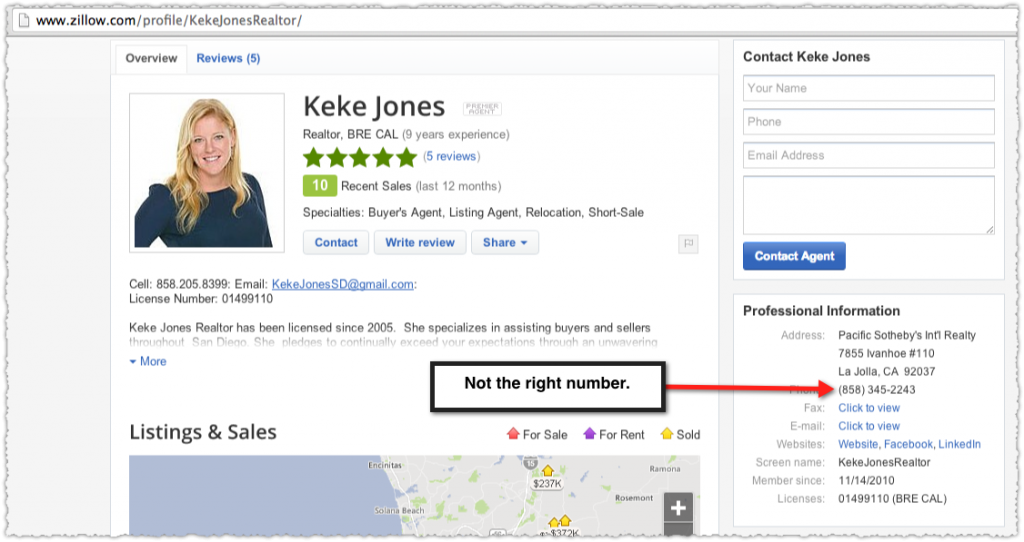
Here the phone number on Zillow doesn’t match the one on Google+ or Google Maps. A quick aside that you’re also seeing the potential to create a relationship between Keke Jones (person) and Pacific Sotheby’s Int’l Realty (place). But I digress.
Outside of the website connection and address match in that Professional Information section, the other reason this result shows up for this search is because they use Zillow products on their website.
The rest of you can run away of these types of implementations based on poor analysis of a Matt Cutts video if you like, but that would be a mistake in my view.
Okay, one last example. Lets zoom in and find another result.
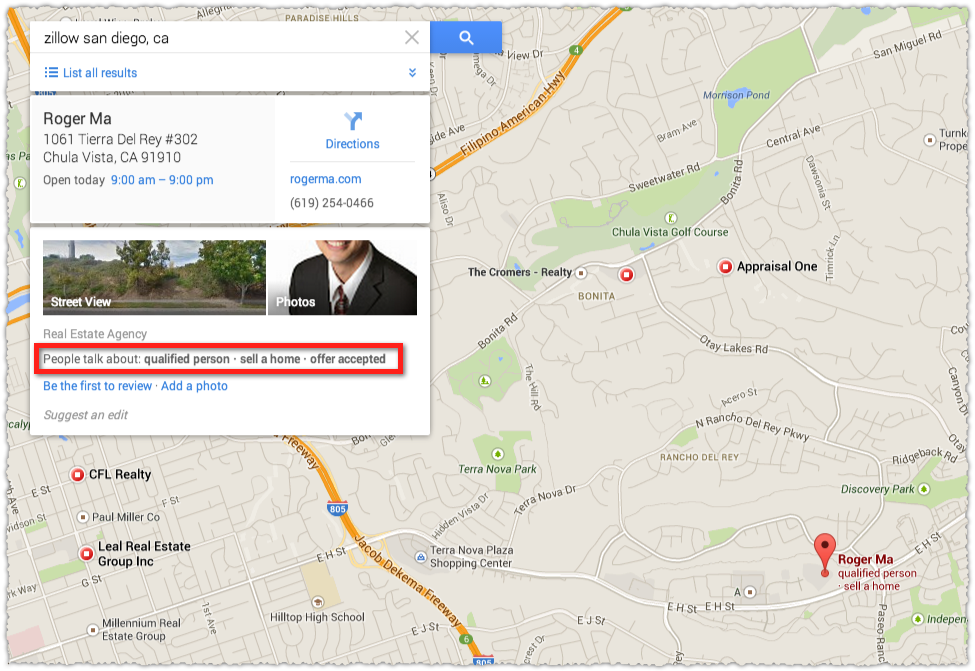
The hours data indicates that Roger probably has a Google+ Page. Yup.
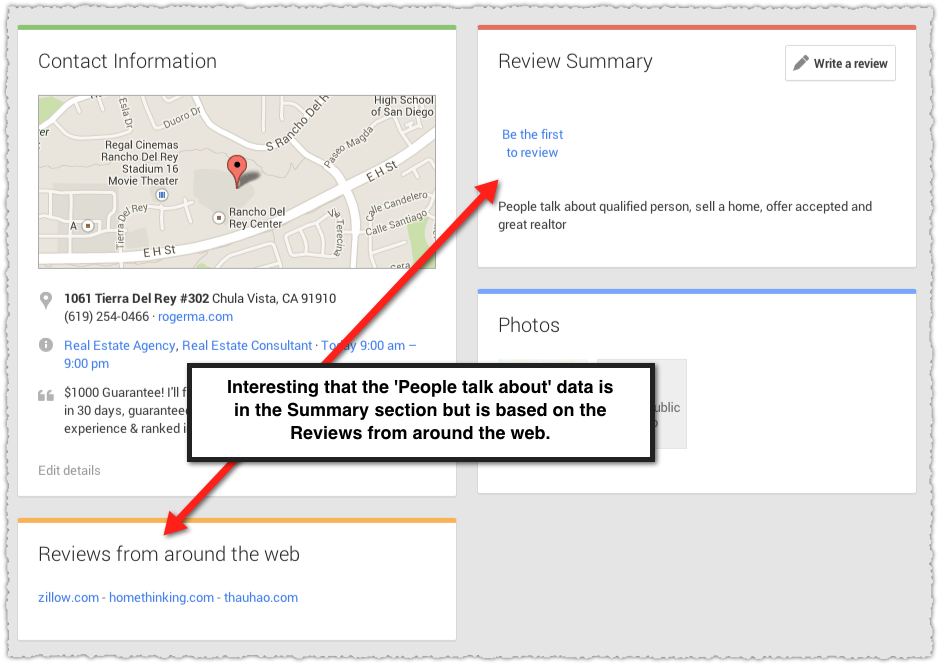
Now we can see that they’re pulling in reviews from Zillow and Roger does have a profile on Zillow. So why he shows up for a Zillow+Geography search is pretty straight-forward.
Interestingly, searching for ‘homethinking san diego, ca’ on Google Maps does not return Roger Ma. Perhaps because they don’t include an address line 1 or because they only use hreview-aggregate and don’t declare a schema.org scope (thank you handy structured data testing tool bookmarklet).
Tough to say but you can see how important it might be to ensure you did what was necessary to confirm these connections.
People Talk About
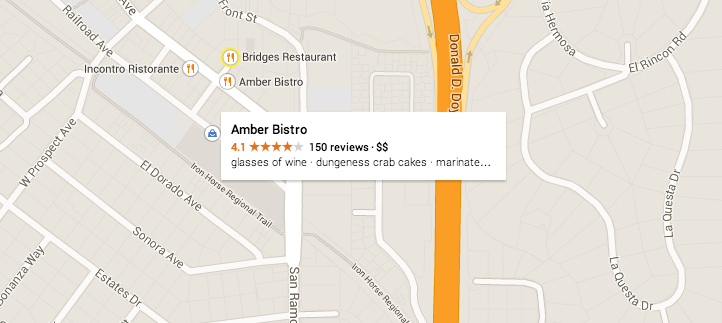
Now lets home in (pun intended) on the ‘People talk about’ feature. These terms are generated though some process/algorithm that analyzes the review text and pulls out the relevant (depending on who you ask) key phrases.
Now, I’m not going to go too far down this rabbit hole, though I think it’s possible Google might be using both review text and query syntax to create these phrases. Bill Slawski did a nice job teasing out how Google finds ‘known for’ terms for entities.
What’s important in my view is that these key phrases become more meta information that gets passed back and forth through entity connections.
Google is assigning this entity (Roger Ma) a certain cluster of key phrases including ‘sell a home’ and ‘great realtor’. Zillow is connected to this entity, as we’ve demonstrated, which means that those key phrases are, on some level, applied to Zillow’s page and site.
Now imagine the aggregated key phrases from connected entities that are flowing into Zillow. Do you think that might give Google a better idea of exactly when and for what queries they should return Zillow content?
And Google might very well know the terms people used to get to Roger Ma’s page on Zillow and use that to inform all of the other connected entities. That’s speculation but it’s made with over six months of experimentation and observation.
I can’t share many of the details because I’m under various NDAs, but once you make these connections using structured data there seems to be an increased ability to rank for relevant terms.
SameAs
Okay, we veered off a bit into theory so lets get back to tactics. If you have a page that is about a known entity you may want to use the SameAs schema.org property.

If I had to describe it plainly, I’d say sameAs acts as an entity canonical. Sure, it’s a bit more complicated than that and has a lot to do with confirming identity but in my experience using sameAs properly can be a valuable (and more direct) way of telling search engines what entity that page contains or represents.
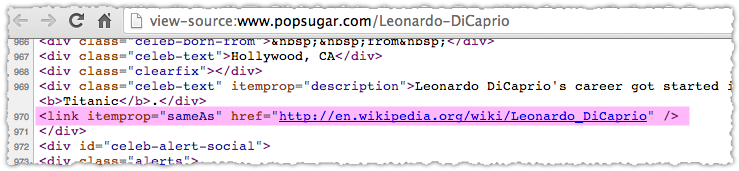
Here you see that a page about Leonardo DiCaprio a sameAs property to his Wikipedia entry. Now, obviously you could try to spam this property but there would be a number of ways to catch this type of behavior. Sadly, I know that won’t stop some of you.
Wikipedia

Like it or not Wikipedia is still a primary source of data for the Knowledge Graph. If you’ve got a lot of time, patience and can be objective rather than subjective you can wade into Wikipedia to help create company profiles, provide reference links (more important than you may imagine) and generally ensure that your brand is represented in as many legitimate places as possible.
Your goal here isn’t to spam Wikipedia but to simply crack the Kafka-like nature of Wikipedia moderation and provide a real representation of your site or brand that adds value to the entire corpus and platform.
Freebase
Freebase on the other hand has a different type of challenge. Instead of obstinate editors and human drama, Freebase is just … a byzantine structure of updates. The good news? It’s a direct line to the Knowledge Graph.
For instance if you search for Twitter this is the Knowledge Card you get as a result.
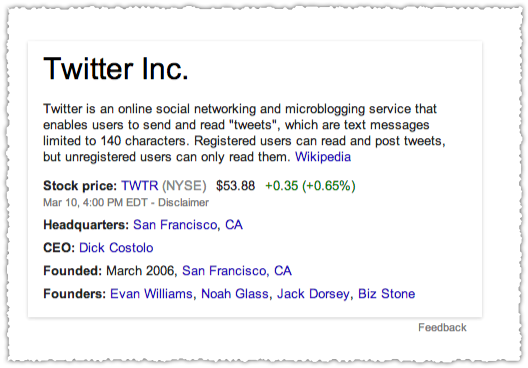
There’s no Google+ part of the Knowledge Card because there is no reference to a Google+ Page under Social Media Presence.
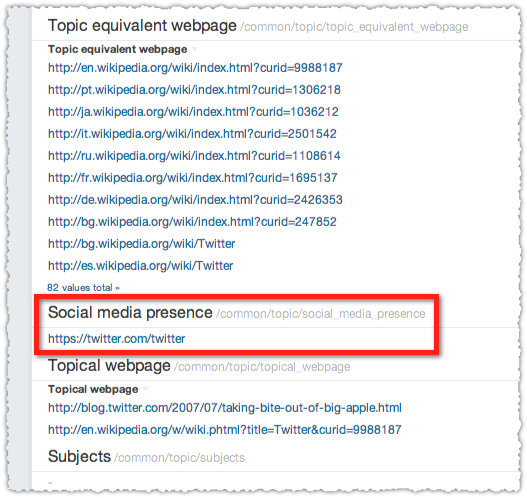
Turns out they don’t have a Google+ Page. Seriously? Man, get with it Twitter. Compare this to StumbleUpon.
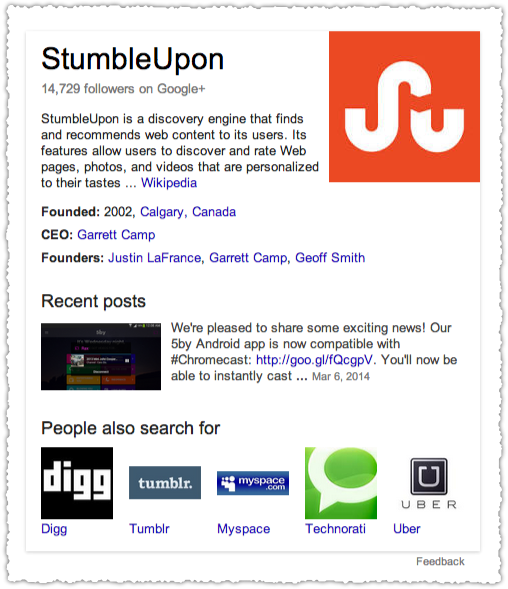
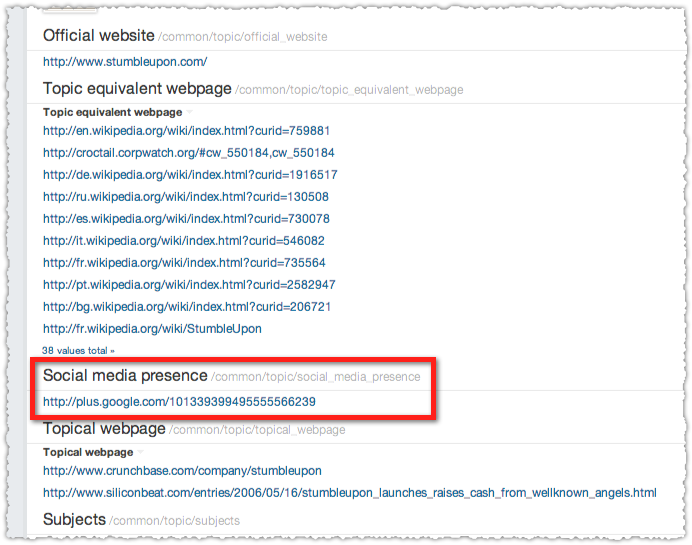
They’ve got the business specific information as well as the Google+ integration with the Recent posts unit. Why? They’ve got a Google+ entry in their Social Media Presence on Freebase.
How about Foursquare?
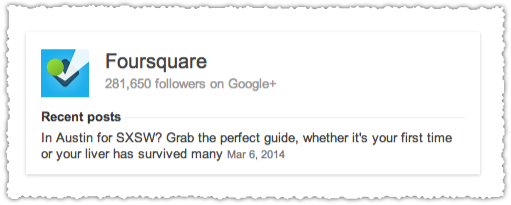
Oy! Not so good. They’ve got their Google+ account in Freebase.
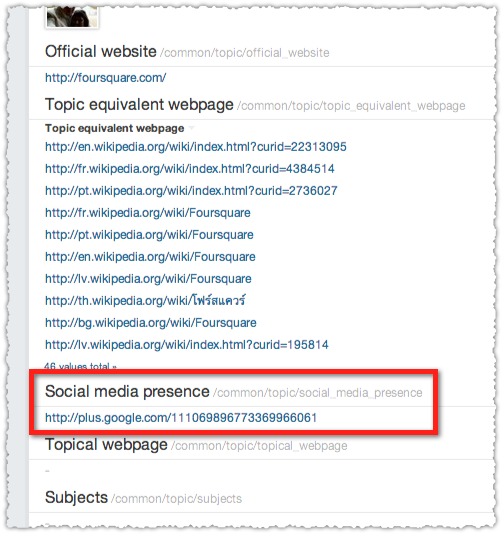
However, the business section on their ‘Inc.’ entry in Freebase (different from the standard entry) is empty.
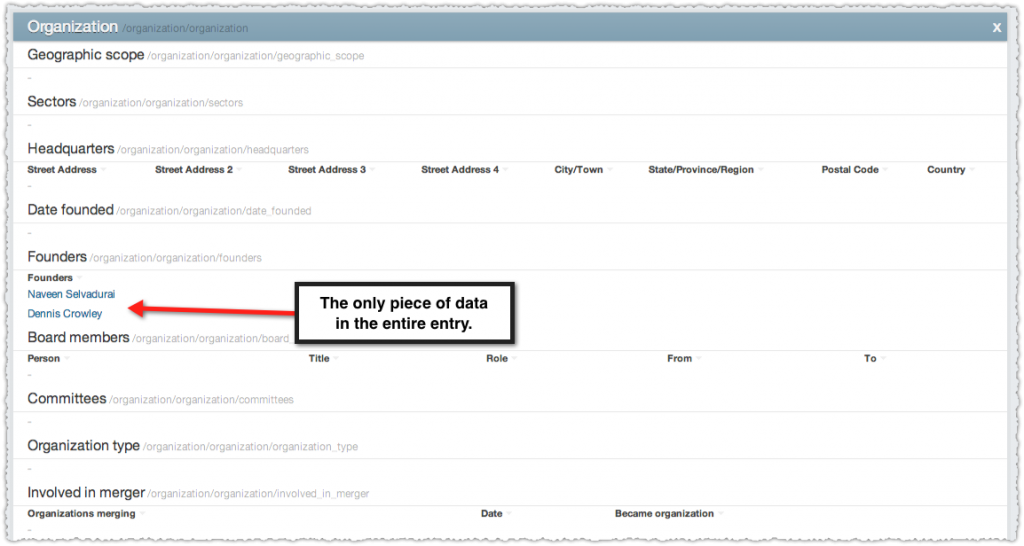
Now, the interplay between a standard entry and a business entry on Freebase can be strange and some entities don’t even need this dual set-up, which makes understanding how to enter it all really complex. So, it’s not just you who thinks updating Freebase is hard. But … it’s totally worth it.
Because Freebase really is where the Knowledge Graph flows as I’ve just shown. For just one more example, look at the Knowledge Card for Garret Dillahunt and then look at the data in his Freebase entry. Match the elements that show up in the Knowledge Card. Convinced?
You might ask why Google links to Wikipedia in the Knowledge Cards and not Freebase? Have you looked at Freebase!? It’s not a destination site anyone on the Google search team would wish on a user. That and Wikipedia has a solid brand that likely resonates with a majority of users.
KGO
Knowledge Graph Optimization is just getting started but here are the real things (pun intended) you can do to start meeting this new world head on.
Use Entities (aka Nouns) In Your Writing
Make it easy for users and search engines to know what you’re talking about by using the actual names of the entities in your writing.
Get Connected and Link Out To Relevant Sites
Stop hoarding link juice and link out to relevant sites so that the entity information can begin to flow between sites.
Use Structured Data To Increase Entity Detection
Make it easier for search engines to detect, extract and connect entities to the Knowledge Graph by using various forms of structured data.
Go A Step Further and Use the sameAs Property
When appropriate use the sameAs property to reference the exact Freebase or Wikipedia entry for that entity. Think of it as an entity canonical.
Claim and Optimize Your Google+ Presence
There’s no doubt that Google+ sits in the middle of a lot of the knowledge graph, particularly about places. So claim and optimize your presence, which also extends to getting reviews.
Get Exposure on Wikipedia
Put on some music and slug it out with Wikepedians who seem straight from Monty Python’s Argument sketch and edit your profile and add some appropriate references.
Edit and Update Your Freebase Entry
Update your Freebase entry and make it as complete as possible. I hope to have a more instructive post on editing Freebase some time in the near future.
Knowledge Graph Optimization (KGO) is about making it easy to connect to as many relevant entities as possible so that search engines better understand your site on a ‘thing’ level and can pass important meta information between connected entities.
The Next Post: SEO Is Stone Soup
The Previous Post: What I Learned in 2013

25 trackbacks/pingbacks
Comments About Knowledge Graph Optimization
// 24 comments so far.
Andy Beard // March 10th 2014
For me the sweet spot has always been to become a notable tag space / topical website.
e.g. Crunchbase in many ways was the most significant decision/achievement for Techcrunch (plus some other nice benefits)
AJ Kohn // March 11th 2014
Andy,
Thanks for the comment. (I had to rescue it from spam!) I agree that being a notable tag space, topical website or hub is a great strategy. In many ways, it’s like About.com’s old bowtie strategy. But the Crunchbase example is quite good because of the density of entities, from the actual business to the investors to executives.
I’ll have to check to see if Crunchbase is taking full advantage of that opportunity.
Bob Gladstein // March 11th 2014
Thanks for this, and I’m looking forward to a post concentrating on Freebase. I find myself in the weird situation of working for one side of a company that’s in two barely connected businesses, and having the Knowledge Graph treat my side’s site as the site of the other side, and the other side’s site as nothing (a non-entity, I guess you could say).
So far, creating a Freebase entry doesn’t appear to have helped (it’s been about a month), and I’m thinking about how many changes I can get away with on the Wikipedia page.
AJ Kohn // March 11th 2014
Bob,
Thanks for your comment and sharing your experience. Freebase is certainly dense and it often takes a long time for things to cure. In the interim, Wikipedia is a fine alternative, though clearly maddening at times.
Rick Bucich // March 11th 2014
AJ –
I didn’t look forward to read this because of the natural knee jerk industry reaction to attempt to game any techniques that may lead to greater search engine visibility.
That said, I find the concepts fascinating! The Entity Challenge that you mentioned in particular was full of great data when reviewing the backgrounds and specialties of the engineers involved.
One of the ideas that really grabbed my attention was the effort to identify pronouns and slang terms associated with entities rather than simply phrases. This is an important element in any effort to extract brand attributes.
Excellent work as usual.
AJ Kohn // March 11th 2014
Thanks Rick. I’m surprised that we haven’t seen more abuse of the Knowledge Graph already. Part of me thinks both Wikipedia and Freebase are purposefully difficult for just this reason.
And yes, search engines are getting a lot smarter in how they extract entities from text. Pronouns and slang terms are being leveraged more and more, but I still hope people don’t rely on them understanding it (at a deep level) anytime soon.
Your comment about brand attributes is also intriguing and you could mash up certain types of actions and sentiments once you can accurately identify those entities. For me, I wonder if there’s work on matching the way the same entity appears in a search query versus written text and mapping that relationship.
Phil Rozek // March 11th 2014
Great stuff, AJ.
I like the “use nouns” strategy. One piece of real low-hanging fruit might be to use the third-person voice on your “About Us” page, “History” page, etc. It doesn’t have to be stuffy. But it would tell Google & co. what “entity” you’re talking about. H/T to Andy Beal for mentioning this idea (in a different context) in his “Repped” book.
AJ Kohn // March 12th 2014
Thanks Phil.
And yes, the third-person voice is certainly a way you can include more nouns with greater ease. The odd thing, which I don’t mention here but is absolutely true, is that users also appreciate the use of nouns. They’re skimming more than reading and nouns are sign-posts for them to stop.
I often ask people whether they’d be able to understand the dialog between 4 people in a book without names (aka nouns).
Gab Goldenberg // March 12th 2014
AJ I just wanted to compliment you as this is one of the best pieces of SEO blogging I’ve read in the past 6 months. I’ve bookmarked (in my browser, I’m old fashioned like that) and plan to write a follow up.
AJ Kohn // March 12th 2014
Thanks so much Gab. Glad you enjoyed it look forward to seeing your follow-up.
Brent Carnduff // March 12th 2014
Hey AJ – really great information here- thanks for assembling and sharing.
Brent
Petra // March 12th 2014
I just discovered that, if I search for our agency in Google Maps, I get shown a lot of our customers. The entity connection is the “made by” on their webpage.
AJ Kohn // March 12th 2014
That’s a great and interesting example Petra. Thank you for sharing that!
Jack Thornburg // March 13th 2014
Thanks, AJ!
I’m wondering why, using your Foursquare example, Google can’t find the Inc. information elsewhere. Foursquare’s a clear entity that’s been around quite some time. Shouldn’t Google be making those connections? Does Google not trust the info on sites like CrunchBase or even Foursquare’s “About Us” page?
AJ Kohn // March 13th 2014
Good question Jack. The structure of Freebase is complex. There are reasons for the structure and complexity, but it’s hard to describe quickly. I hope I can get that post out about editing Freebase soon. It might help clear some things up.
But confidence that the data is right is obviously a priority and then it’s just a product of having so much to do. It’s a pretty crazy big undertaking.
Todd // March 13th 2014
“The entities that are contained on one page are transmitted to linked pages and vice versa.”
I had a big response written out to this..but I think I’d rather just ask:
Can you give an example of how you see this impacting search results?
AJ Kohn // March 15th 2014
Todd,
It’s unclear how much it’s making a difference now but in the future I think about it this way. The entities contained on one page can be classified by topic and authority at some point. So the general topic modeling of pages and sites can be used to better understand relationships.
If a post mentioned a few basketball players and then that post linked to a sports site, the entity information of those players might be transferred to the other site even if the link doesn’t mention them. In general, it would allow Google to understand the strength of relationships between those entities.
The result would be a far more specific and granular view of topic authority.
Todd // March 19th 2014
I think I’m with you now, thanks AJ.
Nevyana Karaksheva // April 22nd 2014
Perfect piece AJ,
It is a great advice to use nouns when preparing your website content, even if I do not get it why Bulgaria is not a proper noun in your mock-up image to the entity tip;)
The sameas markup is really interesting tip, I am curious whether appointing a high authority website (page) different from Wikipedia would have positive results as well, or the impact will be decreased. Or maybe it will be a plus if the given website is also accepted in Freebase.
Supref // May 16th 2014
Hi, I am very interested in KGO and this article just gave me the informations I needed in order to maximise my chances of being quoted in Google’s Knowledge Graph, thanks a lot.
Shawn Cohen // May 27th 2014
Hey AJ,
Thanks for sharing your insights. I have a question about schema markup–it’s easy to sell clients on some markup implementation b/c it directly appears in the SERPs (like image, video, ratings, reviews, etc.) but I have a harder time selling other markup (like “ExerciseAction” or “realEstateAgent”).
Would you encourage websites to “mark up everything” b/c it fleshes out the entities on the site better even though a lot of the tags won’t appear to the user in the SERPs?
Simon // June 18th 2014
AJ, waiting with baited breath for your article on Freebase. I wrestled with it for a couple of days, and it pains me to say I got nowhere. I do plan on revisiting it, but man, is it painful!
AJ Kohn // June 20th 2014
It’s second in line to another post I’m working on which I hope to have out next week. So hopefully by July 4th I’ll have a tentative Freebase editing guide.
Shane O'Connor // October 06th 2014
Hi AJ
As a long serving Wikipedia editor i can relate to your Monty Python analogy 😛
In the moderators forum we’ve really noticed an upswing in the amount of local businesses trying to slip their links in on the platform. Given the date of this article it would suggest that a lot of your musing have panned out. It’s a shame as we would rather be working to improve the resource references and information than be on the front line against Spam.
Thanks AJ and now i’ve discovered your blog i’ll be popping back and contributing where i can.
Regards
Shane
Sorry, comments for this entry are closed at this time.
You can follow any responses to this entry via its RSS comments feed.