Crawl optimization should be a priority for any large site looking to improve their SEO efforts. By tracking, monitoring and focusing Googlebot you can gain an advantage over your competition.
Crawl Budget

It’s important to cover the basics before discussing crawl optimization. Crawl budget is the time or number of pages Google allocates to crawl a site. How does Google determine your crawl budget? The best description comes from an Eric Enge interview of Matt Cutts.
The best way to think about it is that the number of pages that we crawl is roughly proportional to your PageRank. So if you have a lot of incoming links on your root page, we’ll definitely crawl that. Then your root page may link to other pages, and those will get PageRank and we’ll crawl those as well. As you get deeper and deeper in your site, however, PageRank tends to decline.
Another way to think about it is that the low PageRank pages on your site are competing against a much larger pool of pages with the same or higher PageRank. There are a large number of pages on the web that have very little or close to zero PageRank. The pages that get linked to a lot tend to get discovered and crawled quite quickly. The lower PageRank pages are likely to be crawled not quite as often.
In other words, your crawl budget is determined by authority. This should not come as a shock. But that was pre-Caffeine. Have things changed since?
Caffeine

What is Caffeine? In this case it’s not the stimulant in your latte. But it is a stimulant of sorts. In June of 2010, Google rebuilt the way they indexed content. They called this change ‘Caffeine’ and it had a profound impact on the speed in which Google could crawl and index pages. The biggest change, as I see it, was incremental indexing.
Our old index had several layers, some of which were refreshed at a faster rate than others; the main layer would update every couple of weeks. To refresh a layer of the old index, we would analyze the entire web, which meant there was a significant delay between when we found a page and made it available to you.
With Caffeine, we analyze the web in small portions and update our search index on a continuous basis, globally. As we find new pages, or new information on existing pages, we can add these straight to the index. That means you can find fresher information than ever before—no matter when or where it was published.
Essentially, Caffeine removed the bottleneck for getting pages indexed. The system they built to do this is aptly named Percolator.
We have built Percolator, a system for incrementally processing updates to a large data set, and deployed it to create the Google web search index. By replacing a batch-based indexing system with an indexing system based on incremental processing using Percolator, we process the same number of documents per day, while reducing the average age of documents in Google search results by 50%.
The speed in which Google can crawl is now matched by the speed of indexation. So did crawl budgets increase as a result? Some did, but not as much as you might suspect. And here’s where it gets interesting.
Googlebot seems willing to crawl more pages post-Caffeine but it’s often crawling the same pages (the important pages) with greater frequency. This makes a bit of sense if you think about Matt’s statement along with the average age of documents benchmark. Pages deemed to have more authority are given crawl priority.
Google is looking to ensure the most important pages remain the ‘freshest’ in the index.
Time Since Last Crawl
What I’ve observed over the last few years is that pages that haven’t been crawled recently are given less authority in the index. To be more blunt, if a page hasn’t been crawled recently, it won’t rank well.
Last year I got a call from a client about a downward trend in their traffic. Using advanced segments it was easy to see that there was something wrong with their product page traffic.
Looking around the site I found that, unbeknownst to me, they’d implemented pagination on their category results pages. Instead of all the products being on one page, they were spread out across a number of paginated pages.
Products that were on the first page of results seemed to be doing fine but those on subsequent pages were not. I started to look at the cache date on product pages and found that those that weren’t crawled (I’m using cache date as a proxy for crawl date) in the last 7 days were suffering.
Undo! Undo! Undo!
Depagination
That’s right, I told them to go back to unpaginated results. What happened?
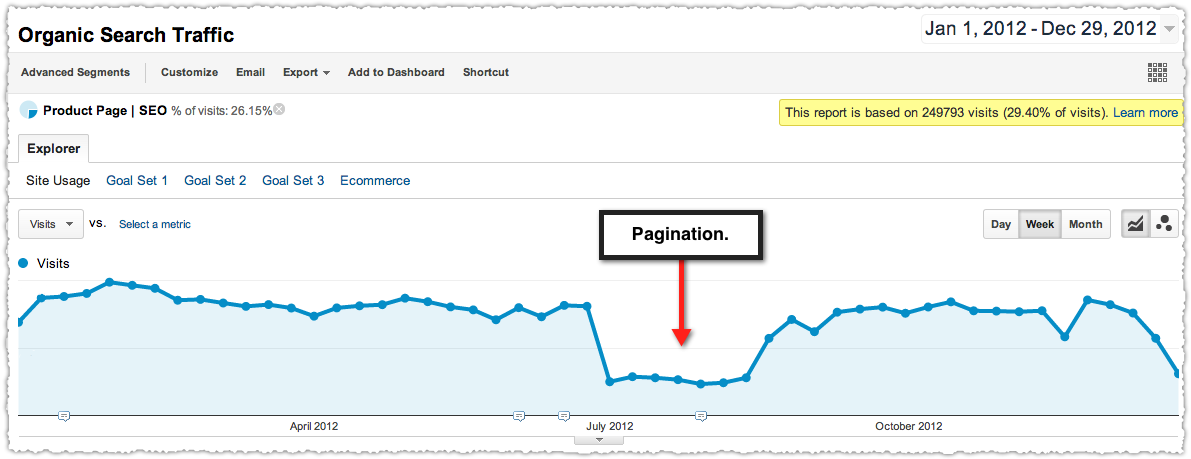
You guessed it. Traffic returned.
Since then I’ve had success with depagination. The trick here is to think about it in terms of progressive enhancement and ‘mobile’ user experiences.
The rise of smartphones and tablets has made click based pagination a bit of an anachronism. Revealing more results by scrolling (or swiping) is an established convention and might well become the dominant one in the near future.
Can you load all the results in the background and reveal them only when users scroll to them without crushing your load time? It’s not always easy and sometimes there are tradeoffs but it’s a discussion worth having with your team.
Because there’s no better way to get those deep pages crawled by having links to all of them on that first page of results.
CrawlRank
Was I crazy to think that the time since last crawl could be a factor in ranking? It turns out I wasn’t alone. Adam Audette (a smart guy) mentioned he’d seen something like this when I ran into him at SMX West. Then at SMX Advanced I wound up talking with Mitul Gandhi, who had been tracking this in more detail at seoClarity.
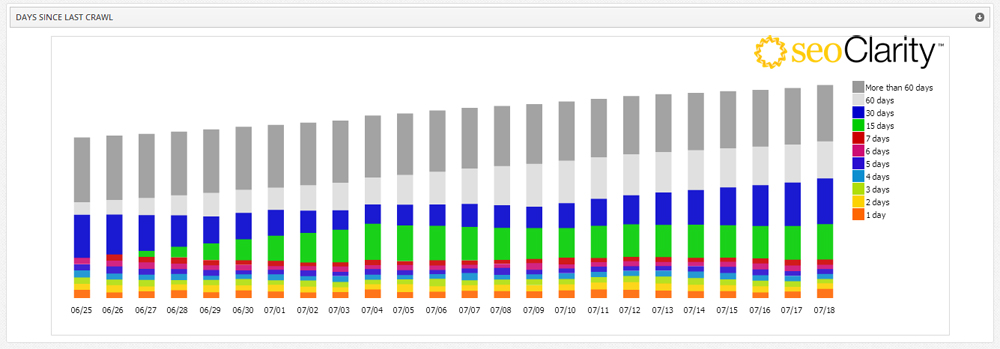
Mitul and his team were able to determine that content not crawled within ~14 days receives materially less traffic. Not only that, but getting those same pages crawled more frequently produced an increase in traffic. (Think about that for a minute.)
At first, Google clearly crawls using PageRank as a proxy. But over time it feels like they’re assigning a self-referring CrawlRank to pages. Essentially, if a page hasn’t been crawled within a certain time period then it receives less authority. Let’s revisit Matt’s description of crawl budget again.
Another way to think about it is that the low PageRank pages on your site are competing against a much larger pool of pages with the same or higher PageRank. There are a large number of pages on the web that have very little or close to zero PageRank.
The pages that aren’t crawled as often are pages with little to no PageRank. CrawlRank is the difference in this very large pool of pages.
You win if you get your low PageRank pages crawled more frequently than the competition.
Now what CrawlRank is really saying is that document age is a material ranking factor for pages with little to no PageRank. I’m still not entirely convinced this is what is happening, but I’m seeing success using this philosophy.
Internal Links
One might argue that what we’re really talking about is internal link structure and density. And I’d agree with you!
Not only should your internal link structure support the most important pages of your site, it should make it easy for Google to get to any page on your site in a minimum of clicks.
One of the easier ways to determine which pages are deemed most important (based on your internal link structure) is by looking at the Internal Links report in Google Webmaster Tools.
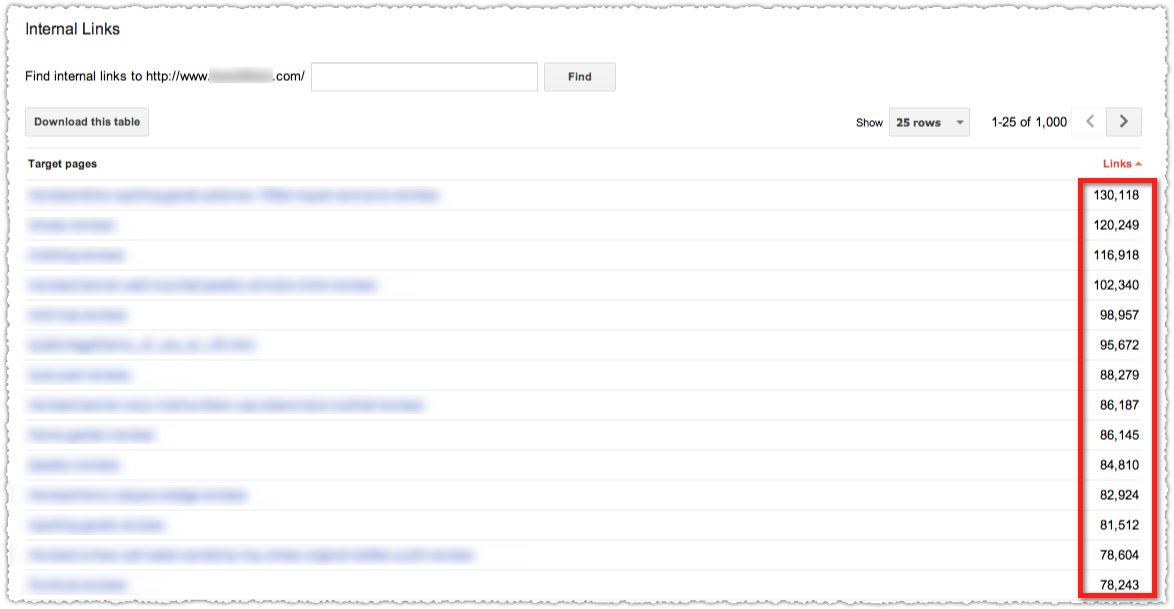
Do the pages at the top reflect the most important pages on your site? If not, you might have a problem.
I have a client whose blog was receiving 35% of Google’s crawl each day. (More on how I know this later on.) This is a blog with 400 posts amid a total content corpus of 2 million+ URLs. Googlebot would crawl blog content 50,000+ times a day! This wasn’t where we wanted Googlebot spending its time.
The problem? They had menu links to the blog and each blog category on nearly all pages of the site. When I went to the Internal Links report in Google Webmaster Tools you know which pages were at the top? Yup. The blog and the blog categories.
So, we got rid of those links. Not only did it change the internal link density but it changed the frequency with which Googlebot crawls the blog. That’s crawl optimization in action.
Flat Architecture

Remember the advice to create a flat site architecture. Many ran out and got rid of subfolders thinking that if the URL didn’t have subfolders then the architecture was flat. Um … not so much.
These folks destroyed the ability for easy analysis, potentially removed valuable data in assessing that site, and did nothing to address the underlying issue of getting Google to pages faster.
How many clicks from the home page is each piece of content. That’s what was, and remains, important. It doesn’t matter if the URL is domain.com/product-name if it takes Googlebot (and users) 8 clicks to get there.
Is that mega-menu on every single page really doing you any favors? Once you get someone to a leaf level page you want them to see similar leaf level pages. Related product or content links are the lifeblood of any good internal link structure and are, sadly, frequently overlooked.
Depagination is one way to flatten your architecture but a simple HTML sitemap, or specific A-Z sitemaps can often be very effective hacks.
Flat architecture shortens the distance between authoritative pages and all other pages, which increases the chances of low PageRank pages getting crawled on a frequent basis.
Tracking Googlebot
“A million dollars isn’t cool. You know what’s cool? A billion dollars.”
Okay, Sean Parker probably didn’t say that in real life but it’s an apt analogy for the difference in knowing how many pages Googlebot crawled versus where Googlebot is crawling, how often and with what result.
The Crawl Stats graph in Google Webmaster Tools only shows you how many pages are crawled per day.
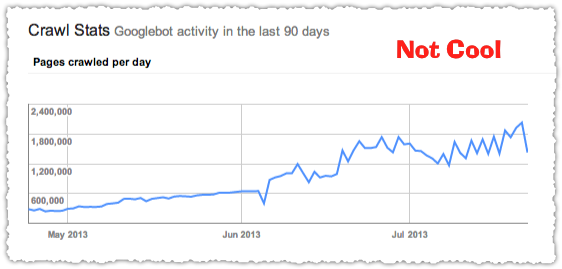
For nearly five years I’ve worked with clients to build their own Googlebot crawl reports.
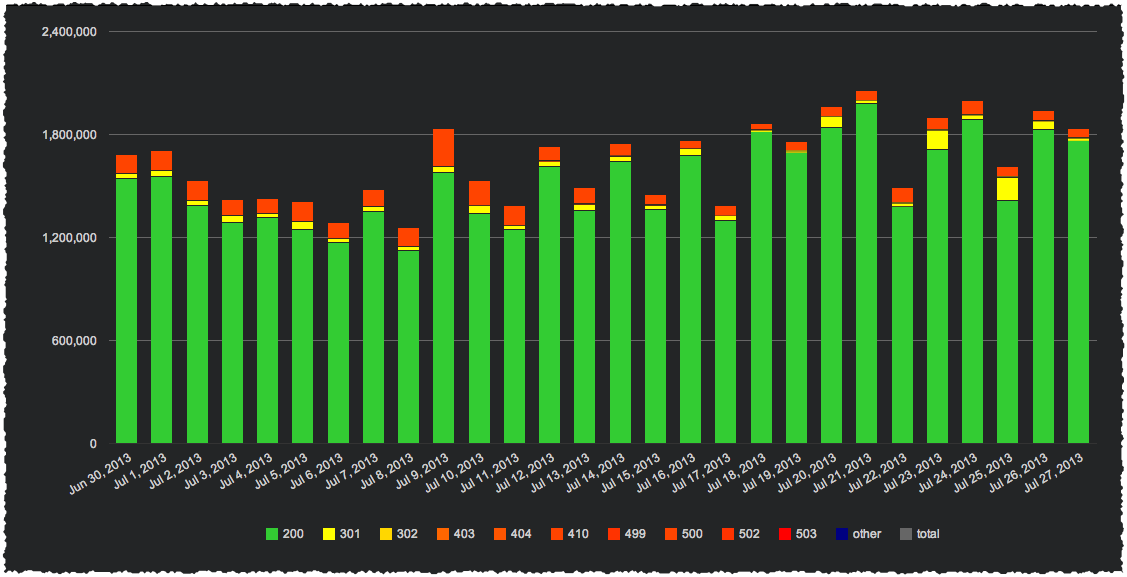
That’s cool.
And it doesn’t always have to look pretty to be cool.
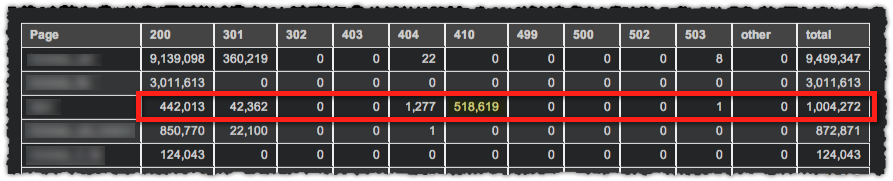
Here I can tell there’s a problem with this specific page type. More than 50% of the crawl on that page type if producing a 410. That’s probably not a good use of crawl budget.
All of this is done by parsing or ‘grepping‘ log files (a line by line history of visits to the site) looking for Googlebot. Here’s a secret. It’s not that hard, particularly if you’re even half-way decent with Regular Expressions.
I won’t go into details (this post is long enough as it is) but you can check out posts by Ian Lurie and Craig Bradford for more on how to grep log files.
In the end I’m interested in looking at the crawl by page type and response code.
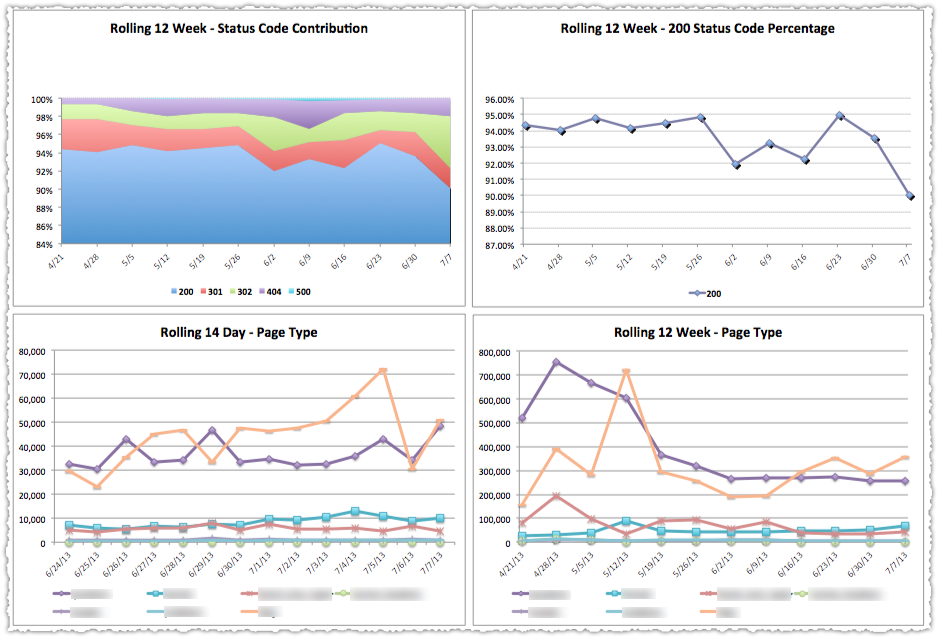
You determine page type using RegEx. That sounds mysterious but all you’re doing is bucketing page types based on pattern matching.
I want to know where Googlebot is spending time on my site. As Mike King said, Googlebot is always your last persona. So tracking Googlebot is just another form of user experience monitoring. (Referencing it like this might help you get this project prioritized.)
You can also drop the crawl data into a database so you can query things like time since last crawl, total crawl versus unique crawl or crawls per page. Of course you could also give seoClarity a try since they’ve got a lot of this stuff right out of the box.
If you’re not tracking Googlebot then you’re missing out on the first part of the SEO process.
You Are What Googlebot Eats

What you begin to understand is that you’re assessed based on what Googlebot crawls. So if they’re crawling a whole bunch of parameter based, duplicative URLs or you’ve left the email-a-friend link open to be crawled on every single product, you’re giving Googlebot a bunch of empty calories.
It’s not that Google will penalize you, it’s the opportunity cost for dirty architecture based on a finite crawl budget.
The crawl spent on junk could have been spent crawling low PageRank pages instead. So managing your URL Parameters and using robots.txt wisely can make a big difference.
Many large sites will also have robust external link graphs. I can leverage those external links, rely less on internal link density to rank well, and can focus my internal link structure to ensure low PageRank pages get crawled more frequently.
There’s no patent right or wrong answer. Every site will be different. But experimenting with your internal link strategies and measuring the results is what separates the great from the good.
Crawl Optimization Checklist
Here’s a quick crawl optimization checklist to get you started.
Track and Monitor Googlebot
I don’t care how you do it but you need this type of visibility to make any inroads into crawl optimization. Information is power. Learn to grep, perfect your RegEx. Be a collaborative partner with your technical team to turn this into an automated daily process.
Manage URL Parameters
Yes, it’s confusing. You will probably make some mistakes. But that shouldn’t stop you from using this feature and changing Googlebot’s diet.
Use Robots.txt Wisely
Stop feeding Googlebot empty calories. Use robots.txt to keep Googlebot focused and remember to make use of pattern matching.
Don’t Forget HTML Sitemap(s)
Seriously. I know human users might not be using these, but Googlebot is a different type of user with slightly different needs.
Optimize Your Internal Link Structure
Whether you try depagination to flatten your architecture, re-evaluate navigation menus, or play around with crosslink modules, find ways to optimize your internal link structure to get those low PageRank pages crawled more frequently.
The Next Post: Authorship Is Dead, Long Live Authorship
The Previous Post: Keywords Still Matter

34 trackbacks/pingbacks
Comments About Crawl Optimization
// 86 comments so far.
John Gibb // July 29th 2013
dear AJ
wow! you nailed this one right here…
very insightful article, I’m not that cautious and analytical when it comes to crawling, but it’s good to know that we should take this issue seriously…
I usually instruct the WP sitemap plugin I run to optimize the post architecture and priorities — is this enough?
Also, as far as I remember the Robots.txt file is an empty one, or includes something that instructs the bot to index all pages… is that all there is to it?
Cheers!
AJ Kohn // July 29th 2013
John,
Remember that this is really only going to matter if you have a large site (100K+ pages). In those instances you wouldn’t want to use a WP sitemap plug in but would create those sitemap files yourself and do so in a way that gave you greater insight.
As for robots.txt, an empty file lets any search engine crawl everywhere. It’s a good practice to have a line here that references your sitemap or sitemap index file. But using robots.txt disallow directives can preserve crawl budget for larger sites. For instance, you don’t want Googlebot crawling add to cart links.
Steve Webb // July 29th 2013
This is a great post… well done AJ!
If you manage a larger site (i.e., 100K pages+), one of the easiest ways to manipulate your rankings is by ensuring authority flows through the site correctly.
Yes, link building is important for obtaining more external authority, but most sites are wasting the authority they’ve already established by committing the mistakes you mentioned (e.g., unnecessary pagination, a broken internal link structure, etc.).
Another common issue that appears in your graphs (in the “Tracking Googlebot” section) is authority dilution through internal redirection. For all sites (and especially large ones), those internal 301s/302s are a great way to destroy hard earned authority. Changing a few internal anchors here and there can have a mind boggling impact.
Anyway, great post!
AJ Kohn // July 29th 2013
Thanks Steve.
You’re right. using the authority you already possess and distributing it correctly is all within our control. And it’s very, very powerful.
And I’m glad you saw that redirect bump. That was a big issue for that client and fixing it (or dramatically reducing it at least) did produce results.
Michael Martinez // July 29th 2013
Shortening the distance from crawl entry points to deep content is important. FLAT SITE ARCHITECTURE is disastrous and should be avoided at all costs. What people need to do is draw PageRank in through secondary pages, not just the root URL. It’s this front-door philosophy that paints people into a corner.
You can use the root URL to kickstart sub-section crawl re-allocation but that’s less efficient than attracting natural links toward as many entry points on the site as possible.
You don’t want flat architecture — what you want is to reduce the number of hops from entry points to deep content. A normal, well-designed Website has MANY entry points, not just the root URL.
AJ Kohn // July 29th 2013
I think we’re probably saying the same thing in many ways Michael but might be using different terminology.
To me, shortening the distance from entry points to deep content is creating a flat architecture. And that’s not a mutually exclusive activity from getting external links to interior pages. In fact, as I mention, most sites who could benefit from crawl optimization have a robust external link graph. Leveraging those external links as they flow into your internal link structure is super valuable.
Rob Duckers // July 30th 2013
This is a good comprehensive view of the subject. Whenever someone launches a large site and then wonders why only a handful of their pages are getting traffic, I’ll point them to this post and say “yeah, I said you should have got an SEO involved from the very start…”
AJ Kohn // July 30th 2013
Thanks for the comment Rob. What’s odd is that it’s sometimes difficult to convince sites that this type of deep monitoring will produce results. But it always does!
Matt Gammie // July 30th 2013
Damn fine writing, as ever.
One thought – more and more large sites and their search people seem to be relying on using noindex, follow and / or rel=canonical to either a) gently manipulate the crawler or b) try to retrofit a quick and easy fix onto a duplicate content “issue” (without actually reducing the number of URLs Google’s fetching…).
It can be worth auditing how these have been implemented – you can sometimes find whole directories or subdomains that have been kept out the index with a noindex follow – a common way to misspend the resource that Google’s prepared to allocate to any site, and often a fairly easy thing to fix.
Your comment – “It’s not that Google will penalize you, it’s the opportunity cost for dirty architecture based on a finite crawl budget” – hits the nail on the proverbial. Certain blogs have terrified people about duplicate content, to the point that some search people are happy for Google to crawl hundreds of percent too many URLs, so long as the content is kept out of the index, or referenced out through canonical tags.
AJ Kohn // July 30th 2013
Thank you Matt.
And you’re right about the noindex issue. Too many times sites waste their crawl on pages that will never find their way into the index. Sometimes that could be useful to get other pages crawled but other times it’s just stuff that should either be added as a disallow in robots.txt or removed altogether.
This is similar to the 410 issue I reference in the post as well. You want Googlebot to spend time on pages that you want in the index, not on those they’ll toss out. At a macro level you can think about it as resource allocation and helping Google use their crawl and index resources (which are big but finite) efficiently.
Jon // August 19th 2015
Hi AJ
Good oldish post but still as relevant today. My worry with blocking anything in robots.txt is that if it’s well linked internally then it still soaks up juice. You save crawl budget on 5,000 useless URLs (good) but waste juice because each one has a small amount that could be utilised with a noindex (bad).
Is there a solution I’m missing or is that just the hard decision we need to make?
Not sure if I’m making myself clear there but can provide an example if needed.
Thanks
Jon
Aidan // July 30th 2013
Great post again AJ.
and again you’ve made it seem so freaking obvious that everyone else will now slap their foreheads and say “of course!” or “I knew there was something about the crawl frequency…”
I’m now off to find a copy of that well known publication ‘Grepping for Dummies’.
AJ Kohn // July 30th 2013
Thanks Aidan and I do hope there’s a ‘Grepping for Fun and Traffic’ book out there somewhere.
Giuseppe Pastore // July 30th 2013
Hi AJ,
crawling budget is a very underlooked aspect, I’ve enjoyed a lot reading this post.
Regarding monitoring Googlebot activity, for WordPress based site you might like this little plugin I built: http://en.posizionamentozen.com/resource/wp-bots-analytics/
(you can check bots activity within Google Analytics, so you’ve a plenty of data, and moreover trends over time). If anyone uses it, opinions are obviously welcome.
Backing to the post, maybe I’d also add something about XML sitemaps. Being true priority and changefreq are only a recommendation, I still consider helpful building a correct XML sitemap to guide spiders towards your most important pages. Don’t you think it would be useful?
AJ Kohn // July 30th 2013
Giuseppe,
I’ll have to check out your plugin. Kudos to stepping up and creating. I love that.
For XML sitemaps, I’m a big fan and believe in sitemap index optimization. However, I’ve been told that the priority, last mod and changefreq are essentially disregarded by Google. I think they figured out that too many were using those fields in a spammy manner (i.e. – last mod is always today’s date).
So you can send them but I doubt they’re doing anything and if you’re spending time there, I think it’s time better spent elsewhere.
Sam Harries // July 30th 2013
Excellent points as usual AJ.
Especially the part about grepping log files to generate your own look at how the crawler is seeing the sites. Looks like I have a project for myself this weekend.
AJ Kohn // July 30th 2013
Sam,
Absolutely. If you’ve got a big site I view it as a necessity to track Googlebot.
Giovanni Sacheli // July 30th 2013
Great article that made me think I have to work hard on loggin’
😀
Could you please suggest the best server-log for bot analysis (in your opinion) for apache?
Giuseppe Pastore // July 30th 2013
Well, if we agree they’re important for big websites both to discover indexing issues and where (as your post well point out) and to increase chances your content gets indexed, maybe they aren’t effective for crawl optimization, but a side effect would still be valuable…
Thanks for appreciating my effort with the plugin. As I was saying on WordPress official page, I’ve integrated an existing PHP script and a few WP coding to have it easily usable for everyone (it requires only 2 values in a form).
I hope it will help people understanding if their blogs look interesting for bots 🙂
Marianne Sweeny // July 30th 2013
Greetings and thank you for a most informative article on deconstruction of individual site crawl rate for useful information. I confess to wincing whenever Matt Cutts tells us anything especially when it is tied to the arcana of PageRank. Surely, we cannot believe that even Google with its vastly superior caffeine indexing can calculate the individual PR for a trillion page Web so that the numbers have any meaning. The volatility of results for many queries shows that ranking is ephemeral and tied to a mercurial set of calculations. If Matt wants us to believe that is the PR of 2000, okay then.
AJ Kohn // July 30th 2013
Thanks Marianne. Clearly there’s a lot going on under the hood that we’re not entirely privy to or fully understand.
That said, Caffeine seems to be composed of three major systems: Percolator, Dremel and Pregel. The latter is most interesting in that it allows for the fast computation of graph data (aka PageRank).
How those new capabilities are used in conjunction with other signals to rank documents is another story, but in some ways Caffeine ensured that PageRank could remain a very viable part of the algorithm moving forward.
Victor Pan // July 30th 2013
I’m glad to learn that I’m not crazy for being worried when Google shows that the # of pages crawled has decreased on GWT. Thanks AJ, insightful as always.
I’ve noticed the phenomenon below as well.
“To be more blunt, if a page hasn’t been crawled recently, it won’t rank well.”
It’s what sets me to panic mode when I look at content that needs to be refreshed. Google has lost interest – like a husband who has stopped caring about his wife – so it’s time to make some changes and win his heart back.
Alan Bleiweiss // July 30th 2013
Great article that brings clarity to some of the most often misunderstood or most discounted important considerations in SEO. I only have one issue – the notion of depagination.
I absolutely agree that crawl efficiency can be improved through depagination, however too often site owners or developers get it wrong and screw it up immensely. Also, with proper maximally optimized pagination, I’ve seen great results on client sites – better than depagination when there are hundreds (or thousands) of products in a sub-category.
Its also problematic when a group of products is depaginated through JavaScript that Google gets confused by. And while depagination can work, personally I’ve found it better to have clients stay with pagination but where they execute it properly with rel-next / rel-prev, appending page Titles, URLs, and H1s with “page X”, canonicals for each page in the group and where it’s all supported through proper sectional sub-navigation.
Just my experience.
AJ Kohn // July 31st 2013
Alan,
Thanks for the comment and kind words. Depagination can certainly go wrong and there are plenty of ways sites can optimize pagination to improve crawl efficiency.
I continue to experiment in this area because new devices are popularizing this type of interface. And once the dominant way to access content is via tablets and phones, those users will expect the same type of experience everywhere.
There are a number of clever ways to deliver all the results to non-JS browsers and present results on demand to JS browsers without crushing your load time. Is it easy? No.
There’s also the notion that you don’t have to return all 3,245 results to users or Googlebot if you know you can get them both to those products in a more efficient way. I mean, is anyone really going to page 245?
It’s an important but uncomfortable area of focus for me because I generally like to implement things that benefit users and Googlebot alike and that isn’t always lining up here.
Ehren Reilly // July 30th 2013
Regarding the claim that “content not crawled within ~14 days receives materially less traffic”, it seems like there is a statistical confound with looking at CrawlRank, which is that it is so correlated with PageRank. Pages with higher PageRank get crawled more often. So crawl recency is affected by PageRank — they are not independent, in the statistical sense. And we know that higher PageRank is a major ranking factor. Did this study somehow look at crawl recency but somehow control for PageRank?
Also, the measures you prescribe to improve CrawlRank are also measure that improve PageRank (notably, pointing more links at the page). Is there any way to tease these apart, and identify a benefit to crawl recency over-and-above the benefit of PageRank?
AJ Kohn // July 31st 2013
Ehren,
Very valid points! And I sort of noted that in the piece when I reference that we’re in many ways talking about internal link structure (which is changing the way PageRank is flowing on your site).
Even in my depagination example, could it be that removing that link from a category results page (with a certain amount of PageRank) have reduced the subsequent product pages’s PageRank and caused Google to crawl less. Maybe.
What I can say is that the site in question, nearly all of those category results pages had zero PageRank. Now, they probably had some, just not enough for Google to return a 1 so it may still be about the flow of authority but … it seemed less likely to me.
I’ve also seen instances where simply removing inefficient crawl (robots.txt and URL parameters etc.) and getting a more efficient crawl improved results. I can’t be certain it was crawl recency that made the difference but that seemed to be the Occam’s Razor answer.
I can’t speak for the research that Mitul at seoClarity has done but in our discussions it seemed he’d done quite a bit of work here to try to isolate the variable.
When I look at it in total (including the quote from Matt on the pool of low to no PageRank pages) it makes sense to me. Still doesn’t mean it’s true though.
Dave Ashworth // July 31st 2013
Could the days of conventional menus be over? I consistently see privacy policies, Ts&Cs, about us etc have far more links than over pages because of their presence on top/footer menus across a site – from a user point of view the About Us pages are still important, but from a crawl / user point of view – privacy etc are not so important, so why link to them on every page!?
Let’s say you do have to leave them on the menus, will blocking them in robots see the number of internal links reported in GWT reduce? Or is it just something will have to bear in mind when reviewing internal links?
AJ Kohn // July 31st 2013
Dave,
Good question. The sense I get is that Google has figured most of that out and I am generally not concerned about those links.
Now, if I see that Googlebot is spending an inordinate amount of time on ‘administrative’ pages, I might seek to do something about it.
I will say that I’ve played with making these links available solely to JS browsers or changing the footer (slim on all pages except home) and seen interesting results but nothing I’d write home about.
Julian // July 31st 2013
Hi AJ
Thanks for this post.
I got a question regarding the internal links. What is your experience if I have a-tags without the href-part? You think (or better: have data about this) this is counted as a link and therefore linkjuice is lost?
Regarding the robots.txt:
I wouldn’t use this anymore. Show the link to Google if you want a site to be crawled or don’t show it. Much better way 🙂
Regards
Julian
AJ Kohn // July 31st 2013
Julian,
I’m not quite sure what you’re asking here. Why would you have an empty a tag? What are you trying to accomplish?
And robots.txt isn’t about links. It’s an insanely valuable tool in telling Googlebot where it should not crawl to preserve your crawl budget.
Here’s a great excerpt from a Google Webmaster Central Blog post by Susan Moskwa.
Chris Gedge // July 31st 2013
This is one of the best technical SEO posts I have read this year! I have been trying to explain Google crawl budgets and depths for a long time now, and this really clarifies my thinking. Thanks
AJ Kohn // July 31st 2013
Thanks Chris. I appreciate the feedback and kind words.
Giovanni Sacheli // July 31st 2013
Thanks for this good article. Is there a free log analytics you could suggest to track pages visited by spiders? I mean something like AWstats but more SEO oriented?
AJ Kohn // July 31st 2013
Giovanni,
While I still like to role my own (or get my clients to do so), you might check out Splunk and Log Stash. Not sure what you’ll get for free but I hear good things about these.
Conor // July 31st 2013
Great post as usual AJ,
It’s a timely post too, as I’m looking to have a cron job created to show Google bots activity on our domain(s), represented by daily/weekly/monthly graphs.
Maybe i can follow up with you in due course, show you how it looks.
AJ Kohn // July 31st 2013
Conor,
Thank you sir and ‘cron job’ is music to my ears! And I would be very interested in hearing how it all works out for you.
Conor // July 31st 2013
AJ,
All in due course, I’ve an enormous project ahead of me. Yet, I’ve some very talented engineers at my disposal. So fingers crossed 🙂
Julian // July 31st 2013
AJ
A lot of people in Germany are masking (right word?) the links. So they dont use the href (just an a-tag with e.g. data= which is converted into href=) or using javascript like href=”#”.
My question is, what you think about this. Is this a real link which gets linkjuice or not?
I think it is counted as a link, so I would avoid it and use an span-tag instead.
About the robots.txt
Sure it is about crawling. But Google can only crawl pages with links to it. So, I just dont show the links, then Google dont want to crawl. This is much better than showing links to e.g. the cart.
Only use the robots if you cant change your site. But then, it’s the best way to limit the crawling for the bot.
Nate Turner // August 01st 2013
Great post, AJ.
Thanks for taking the time to lay out the steps & details on tracking crawl performance by page type. I’ve had success recently with robots.txt, but have only been able to see the broad effects.
I think charting crawls by page type looks like a great way to find areas for improvement, but also to understand the impacts of changes with granularity.
Also, interesting point on the shift to mobile and the effects it has on pagination.
AJ Kohn // August 01st 2013
Thanks Nate. I’m glad you found it helpful.
And you hit the nail on the head. When you track by page type you can see the impact of changes you make to the crawl and from there to indexation and traffic.
Ana Hoffman // August 01st 2013
Another pagination question, AJ, for blogs:
I always thought it’s more beneficial to provide pagination to reach deep archive pages from the blog home page, i.e. page 1,2,3,4…..10 etc, rather then just a link to the previous posts.
As you noted somewhere else, a reader might not really care to click over to page 245, but I thought that it actually helps Googlebot crawl those deep pages. Am I wrong?
Unrelated question: any reason you don’t do nested comments? I found it extremely difficult to follow the discussion in the comment thread…
AJ Kohn // August 01st 2013
Ana,
I think the pagination in place on blogs is just fine. Most blogs wouldn’t have a corpus of content that would require a lot of attention to crawl optimization. Mind you, if you’re not seeing the proper crawl rates you might want to tinker.
And I have nested comments on my to-do-list. Long story short, I’m using a theme that predated nested comments on WordPress so even though the feature is ‘on’ the code hook isn’t there. That and a mobile optimized site are my two major site priorities. But for the moment my site is taking a back seat to client sites.
Julian // August 02nd 2013
AH you got my answer? Here an example:
my javascript link
Is this counted as a real link and gets linkjiuce? What is your experience?
Problem is when I have like 100 of this links on a single page and only 50 “real” links with a target.
BNH // August 03rd 2013
Thanks for the informative post. One thing I am not clear on:
Regarding using robots.txt instead of no-index & follow or canonicals for content you don’t want indexed (and can’t remove from your site): I understand that robots.txt is superior in terms of maximizing your crawl budget, but isn’t it at a disadvantage when it comes to maximing PR flow? Links to pages blocked by robots.txt essentially cause you to waste PR, whereas with noindex & follow or canonicals you preserve that PR, no? So really deciding which one to use is a question of trade-offs between CrawlRank and PageRank…
Matthew James // August 04th 2013
Hi AJ,
Thanks for this post – absurdly useful as ever!
Rookie question: I have a similar situation to the one you mentioned above, the internal links report in GWT is dominated by blog categories.
I’m wondering about stripping them out and replacing them with links to our priority/money pages. Theoretically this would replace the priority pages as our top most linked content in GWT, right? Are there any downsides to this? I’m super cautious about “over-optimization” these days, but am not sure if that even applies to internal links.
Thanks again,
Matt
Martin // August 05th 2013
One of the best technical SEO post ! Recently, i found out that one page optimazation is more important in low competition niches. The sites who ranks pretty well even got less than 10 links, but with a good site architecture. Internal link structure needs to pay more attention ! Thanks for sharing such great ideals, AJ !
Spook SEO // August 07th 2013
Great post. Got tons of golden nuggets there. I’m glad that you talked about depagination. I came to realize that that might be what’s causing the drop in traffic on my client’s product page. I’ll try doing the necessary changes tomorrow. I hope it works.
Paul // August 08th 2013
Great post, loads of detail. I have been around a lot of SEO techniques and never seen the analysis this detailed.
Great POST! love it, going to look at my internal link structure now!
Nathan // August 23rd 2013
I am still trying to work my way through the depagination. Building a new site right now, and I want to implement this for my client’s inventory on an e-commerce site.
So here is what I am struggling with. We can load all the results in ample time, and will lazy load the images for each product to keep the speed quick. But How does the mobile Googlebot work? I imagine it would see all the content loaded in the background, and load all the images at once since it sees all the content at one, making Google think our page load time is very slow on mobile.
I was looking at the options on the following post, and agree #4 might be the best option for users. But how will Google handle that? The user finds more as they scroll to the bottom, but will Google?
http://ux.stackexchange.com/questions/7268/iphone-mobile-web-pagination-vs-load-more-vs-scrolling?rq=1
Michelle // August 27th 2013
OK, I’m not a techie person at all but is using the “infinite scroll” structure a form of depagination? I’m trying to improve one of my sites’ link structure so it gets crawled better and I’m thinking of moving away from pagination…
Doc Sheldon // August 27th 2013
Outstanding post, A.J…. one of the best tech. posts I’ve seen in a good while. I only rarely touch sites larger than 20-30K pages, so I may not get to put much of this to use, but understanding the relationship of crawl to flattened navigation can apply to smaller sites to a degree, too.
Dan Shure // August 30th 2013
Question: How do we know this isn’t just CrawlRank Correlating with less traffic? Am I following that lower PR pages get crawled less? And lower PR pages likely don’t get ranked as highly? Maybe we’re just seeing the effects of pages with poor/low link equity?
Dan Shure // August 30th 2013
Actually, I take back my first comment to the extent that you can control PR to a degree via better architecture. Duh, Friday. Never mind 😉
Trey Collier // September 24th 2013
Great post AJ! Started reading it while on phone at a party….well…realized quickly that it needed my undivided attention without any other influences if you get my drift.
You made me look at my sites and I found where every page of my site, due to being careless, points to my onstie blog in 2 places. Talk about a possible Nugget! Not to mention that GWT seems to think my Legal, Privacy, Contact, etc. pages are the most important. UGH!.
CrawlRank sculpting will be done in a day……Hope it helps. Thanks for a great post.
Seo Lysiak // October 02nd 2013
I spend hours ever week reading articles to keep my SEP practices up to date and many time the articles I find are common knowledge or out of date information. This article however is unique and informative and the reason I continue to scour the web to find the gold amongst all the dirt.
Modestos Siotos // December 13th 2013
This is one of the best post I’ve come across in 2013 – Definitely the holy grail of technical SEO.
A few moons ago I had the chance to work on one of the UK’s biggest ecommerce sites and just by blocking parameters from WMT the number of (redundant) indexed pages dropped from 3m down to 1m within a couple of months! Unfortunately, measuring the impact this had on rankings & traffic was very difficult as the client wasn’t keen on sharing any server log data. With this type of sites making sure Googlebot crawls what is worth to be indexed is a no brainer but explaining this to a blue chip client can be very frustrating as they always ask for revenue forecasts etc.
I have one question. In one of the above comments you said “I’ve also seen instances where simply removing inefficient crawl (robots.txt and URL parameters etc.) and getting a more efficient crawl improved results.”
My understanding is that with robots.txt you can directly manipulate how Googlebot spends its allocated crawl budget as you can explicitly tell it which URLs it’s not allowed to crawl. However, when blocking URL parameters in WMT wouldn’t that have an impact on indexation only? I’m not sure whether URLs with blocked parameters in WMT still get crawled and then removed from google’s index or aren’t get crawled at all.
AJ Kohn // December 14th 2013
Thanks Modestos.
URL Parameters are, in many ways, the lite version of robots.txt and can be configured so that URLs with certain parameters aren’t crawled. You can set a URL parameter to No URLs and Google will cease crawling URLs with that parameters but any URLs currently in the index will remain there unless you take other action to remove those parameter based URLs.
So it really is largely for crawl control. Removing URL bloat must be done with an on-page noindex or URL Removal. Sadly, there’s no parameter based URL removal tool at present though I know it’s one of the things potentially on the slate for next year if enough people ask for it.
Dan Shure // December 14th 2013
@AJ @Modestos
I recently learned that URL removal technical does not remove them from the index just search results. John Mueller mentioned this in a recent hangout – the URL removal tool just suppresses them from showing in search but they are still in Google’s index and could return after 6 months so you have to check them.
AJ Kohn // December 17th 2013
Interesting Dan. I’ll have to follow-up with John about that. I’ve had good luck using URL removal, particularly directory level removals, which have been permanent. But clearly the nuclear option for removing content is applying the noindex robots tag. It’s just not particularly feasible in some situations to rely on Googlebot to find hundreds of thousands of backwater URLs.
I think it’s pretty clear that URL parameters is about crawling just by looking at the messaging when configuring a parameter.
Modestos Siotos // December 15th 2013
@AJ @Dan
Thanks for your comments.
It seems that there are mixed opinions about this. In my experience WMT parameter blocking is that it acts more as a de-indexer rather than a crawl-blocker. I would say it’s a lighter version of onpage noindex rather than robots.txt because I have managed several times to remove pages from Google’s index using it.
This also seems to be more in agreement with John Mueller’s comment (thanks Dan – do you have the hangout URL handy BTW?). From a technical implementation perspective it makes more sense that Google has to crawl, index and then suppress the undesired URLs – Implementing this at crawl time would be much more complicated from a technical point of view so robots.txt seems to be the only way to control which pages should not be crawled.
John, have you come across anything from Google confirming that URL parameter blocking is applied at crawl time?
Devin Peterson // March 30th 2014
Must give credit where credit is do. You really did your homework on this post and its very helpful to me. Thanks for taking the time.
I would like to pose a question though, if Google allocates ‘time’ to crawl your site rather than setting a ‘number’ of pages to crawl, then would improving page load speed help increase crawl rate? I have noticed this correlation which leads me to believe they use a time rather than # of pages.
AJ Kohn // March 30th 2014
Devin,
Thanks for the kind words and comment. Yes, improving page load speed can help to get more pages crawled in the same amount of time. It’s slightly difficult to prove because there are so many variables, but I too have seen this correlation and believe there’s likely a causal effect.
Peter // April 05th 2014
Hi AJ,
Great post. It gave me a lot to think about. However, I have a question. Do you think it would be a good idea to “nofollow” images on a website? I’m not talking about a large one – more like a 10 to 15 pages website with 20 or so images?
Thanks,
Peter
AJ Kohn // April 05th 2014
Thanks Peter and no, no reason to nofollow images on a site that small. Let Googlebot see everything. Just be sure the images are optimized (i.e. – file name, alt title, caption etc.)
Yair Spolter // July 17th 2014
Thanks for this fantastic, eye-opening post, AJ!
I was hoping you could answer the question from the comment above:
“Thanks for the informative post. One thing I am not clear on:
Regarding using robots.txt instead of no-index & follow or canonicals for content you don’t want indexed (and can’t remove from your site): I understand that robots.txt is superior in terms of maximizing your crawl budget, but isn’t it at a disadvantage when it comes to maximing PR flow? Links to pages blocked by robots.txt essentially cause you to waste PR, whereas with noindex & follow or canonicals you preserve that PR, no? So really deciding which one to use is a question of trade-offs between CrawlRank and PageRank…”
And what do you say about dealing with pages that I don’t want spidered by making all links to the the page into js links?
Kristian Nielsen // September 02nd 2014
Hi AJ, great article – you take an interesting angle which is contrary to many experts promoting “noindex, follow” in thin content pages in order to preserve the internal link flow. For real estate websites with MLS data, does that mean you would suggest adding categories and specific properties without quality unique content to the robots.txt as opposed to “noind3x, follow”? I have a real estate site and I have about 300 high quality category pages indexed and I have left about 5000 with “noindex, follow”. I assume the robots.txt may make more sense after reading this. Your insight would be appreciated.
Regards
Kristian
AJ Kohn // September 04th 2014
Kristian,
I’m not sure I’d bother with robots.txt for a site with under 10,000 pages. Of course a lot would depend on the crawl behavior. If you’re having issues with getting a full crawl of your high quality pages then you might use robots.txt. But for thin content pages of this nature a ‘noindex,follow’ suffices and helps keep you out of Panda Jail.
Does that help?
Kristian Nielsen // September 04th 2014
thx, AJ. appreciate the good feedback
Will Klopp // December 18th 2014
I too appreciate you article as we try to continuously optimize our real estate website. I wanted to know what you program you use for your Googlebot crawl report?..sounds like you feel GWT is not optimal.
Adam Melson // March 03rd 2015
Great resource as always AJ. I had one question about crawl budget across subdomains. Have you experienced or read any tests looking to see if Google has a crawl budget specific to a subdomain outside of that of the regular site? Thanks!
AJ Kohn // March 03rd 2015
Adam,
Thanks for the kind words. I have had some experience with crawl budget across subdomains. In many cases it seems like Google assigns the crawl budget based on the root domain, meaning that if you get a deep crawl on the subdomain that day you might see a decline in the crawl on the root.
This seems to moderate a bit over time, particularly as the subdomain accrues its own authority, but there still seems to be a crawl budget assigned to *.domain.com overall. Does that make sense?
Adam Melson // March 03rd 2015
Makes perfect sense. With Google treating subdomain links as internal links, having unique budget for the root is where I’m leaning and will be testing shortly. Thanks for the fast reply!
John // July 15th 2015
This was such an extensive and very insightful article. I don’t pay that much attention to crawl budget but after reading this post, I surely will include this as a priority especially when dealing with e-commerce websites.
Manny // July 28th 2015
Hi AJ. This is very helpful.
I’d like to try out your depagination strategy on an ecommerce website. However, there are some categories with several thousands of products under them. Can I get your opinion on what the best strategy is to implement this? I’m a bit concerned that crawlers will ignore some links if a page has thousands of them. There’s also the issue of loading if all products are stuffed into one page. Plus, link equity distribution.
AJ Kohn // August 13th 2015
Manny,
The question here is whether Google can get to all those products in other ways? In other words, do you need to have all the products crawled on that one page?
Thomas // August 31st 2015
Great post…I learned alot but some thing went over my head. And I have a few questions
1) should pages that never change be crawled at a higher rate? What if they are your most valuable pages?
2) Does Google crawl less for pages that hardly/never change?
AJ Kohn // December 21st 2015
Thanks for your comment Thomas. I don’t see a lot of variance in crawl activity based on the page content changing. It’s generally about external and internal links and whether there’s an easy crawl path available to Googlebot.
Jack S // November 04th 2015
Hey AJ,
Thanks for a great post. I’m waking up a little late to the whole world of crawl budgets but am cracking down on it in an intense way now.
I’m looking at one of my sites that runs on WordPress and Google spends like 30% of its time crawling wp-content and wp-includes files (css, js, etc). I don’t want to block it to prevent Google from rendering properly but it seems like a crazy amount.
In the meantime I have told it to ignore the version parameter WordPress sticks on there. Any tips?
Marco Panichi // November 18th 2015
Hi Aj, this post is really useful but I’m a little bit confused:
1) You have blog categories on your sidebar. It isnot helping your blog to have a flat architecture, doesn’t it?
2) You talk as if equals to and I don’t think it is right. On your example above you have a website with 400 posts and 2000000 links. So you conclude that we are asking Googlebot to crawl our website 50000 a day. But I don’t think it is realistic. I think instead that once Googlebot has saved a URL (we have 400 URLs), it will crawl our website only 400 times a day. I’m right or wrong?
3) With a flat architecture how we can ranks for medium-level keywords (example: “car rental”)? I was induce to think (following other posts by wordstream, moz and other blogs) that in order to rank for such keywords I have to create a “hub page” (“cars rental”) and support it with others long-tail pages (example: “cars rental weddings”, “cars rental business”, “cars rental long trip”, …) linked to the hub page itself.
Can you help me about these doubts?
Thank you very much for your post!
AJ Kohn // December 21st 2015
Thanks for your questions Marco. Overall, this is far more valuable for sites with over 100,000 pages. I wouldn’t worry much about crawl optimization for smaller sites. But I’ll answer each of your questions.
1) Meh. I don’t much care in this instance. Google will find them all but it’s good for users and Googlebot so it’s a win win.
2) I don’t follow the first part of your description here. But no, if you have 400 URLs you may get crawled far more than 400 times each day. Google doesn’t visit a URL just once a day. They can visit numerous times and that can often be the problem on larger sites.
3) I’d say that’s a fairly outdated approach. If you had a great ‘car rental’ page that was rich in content, perhaps curated content, and earned valuable links you might be able to rank for that term without all those other pages. Mind you, those other pages might be valuable too and over time they might help your hub page but the sense I get is you’re creating those only for the purpose of getting the hub page to rank and that’s not the right way to think about things.
Dawn Anderson // January 19th 2016
A J,
I love this post. Come back to read it often and it was most helpful to me a couple of years ago whilst fixing an issue with infinite URLs on a site with >1 mill index pages.
Just wondering if you still consider that there’s a correlation on the low (so called page rank) pages and rankings (i.e. so called ‘crawl rank’) or do you have a different view in current search landscape?
AJ Kohn // January 20th 2016
Dawn,
Thanks so much for the kind words. This is definitely one of my own personal favorites.
I still see evidence that getting pages crawled frequently (within 7-10 days) seems to have an impact on their ability to rank well. In general, every time I’ve worked at optimizing crawl efficiency good things happen.
Dawn Anderson // January 20th 2016
Thanks for responding and glad to hear that you still see evidence that crawl optimization.
Me too. I just wanted to check that your thinking hadn’t changed too much since the post was written.
I’m convinced that this is a factor on the huge range of long tailed terms (i.e. low value but lots of combined volume when bucketed together), in large sites.
Researching it in more detail, but there is little out there other than the ‘do crawl optimization’ well and here’s how posts en masse.
I will let you know how I get on and may be back to ask for your view on this again if I may?
Thanks for the prompt response again.
Thanks
Dawn
AJ Kohn // January 20th 2016
Absolutely Dawn. I’d love to get some more eyes on the topic and practice in detail.
Dawn Anderson // January 20th 2016
Interestingly, I just read your piece on Aquisition SEO and crowding. Somehow I feel this ties in with ‘crawl rank’. I’m seeing a big comeback on clustering in some of the verticals I monitor (and have monitored for several years), in many of those long tailed queries again. That seemed to drop away for a while there at one point. I understand that your main point wasn’t that from this piece, however when we look at some of the parent companies behind a lot of these major sites there does look to be a domination occurring there. Just my POV though.
AJ Kohn // January 20th 2016
Thanks Dawn. And you’re right. That’s not really what this piece is about but … obviously the crowd hosting algorithm has seen a lot of fluctuations over the last five years.
There’s a lot of calibration going on in my view as well as balancing feedback (i.e. – I damn well know about Yelp and don’t need 6 results from them) versus the metrics (i.e. – that SERP performs well on a time to long click basis).
Clearly, those sites that can get more pages indexed and crawled more frequently have more bites at the apple.
Sorry, comments for this entry are closed at this time.
You can follow any responses to this entry via its RSS comments feed.