Google’s Authorship program is still a hot topic. A constant string of blog posts, conference sessions and ‘research’ projects about Authorship and the idea that it can be used as a ranking signal fill our community.

Yet, the focus on the actual markup and clock-watching when AuthorRank might show up may not be the best use of time.
Would it surprise you to learn that the Authorship Project at Google has been shuttered? Or that this signals not the death of Authorship but a different method of assigning Authorship.
Here’s my take on where Authorship stands today.
RIP Authorship Project
The Authorship Project at Google was headed up by Othar Hansson. He’s an incredibly smart and amiable guy, who from time to time was kind enough to provide answers and insight into Authorship. I was going to reach out to him again the other day and discovered something.
Othar no longer works on the Authorship Project. He’s now a principal engineer on the Android search team, which is a pretty sweet gig. Congratulations!
Remember that it was Othar who announced the new markup back in June of 2011 and then appeared with Matt Cutts in the Authorship Markup video. His departure is meaningful. More so because I can’t locate a replacement. (That doesn’t mean there isn’t one but … usually I’m pretty good at connecting with folks.)
Not only that but there was no replacement for Sagar Kamdar, who left as product manager of Authorship (among other things) in July of 2012 to work at Google X and, ultimately, Project Loon.
At the time I thought the writing was on the wall. The Authorship Project wasn’t getting internal resources and wasn’t a priority for Google.
Authorship Adoption

The biggest problem with Authorship markup is adoption. Not everyone is participating. Study after study after study show that there are material gaps in who is and isn’t using the markup. Even the most rosy study of Authorship adoption by technology writers isn’t anything to write home about.
Google is unable to use Authorship as a ranking signal if important authors aren’t participating.
That means people like Neil Gaiman and Kevin Kelly wouldn’t rank as well since they don’t employ Authorship markup. It doesn’t take a lot of work to find important people who aren’t participating and that makes any type of AuthorRank that relies on markup a non-starter.
Authorship SERP Benefits
![]()
Don’t get me wrong. Google still supports Authorship markup and there are clear click-through rate benefits to having an Authorship snippet on a search result. Even if you don’t believe me or Cyrus Shepard, you should believe Google and the research they’ve done on social annotations in 2012 (PDF) and 2013 (PDF).
So if you haven’t implemented Google Authorship yet it’s still a good idea to do so. You’ll receive a higher click-through rate and will build authority (different from AuthorRank), both of which may help you rank better over time.
Google knows users respond to Authorship.
Inferred Authorship

It’s clear that Google still wants to do something about identifying authority and expertise. Any monkey with a keyboard can add content to the Internet. So increasingly it’s about who is creating that content and why you should trust and value their opinion.
One of the first ways Google was able to infer identity (aka authorship) was by crawling the public social graph. Rapleaf took the brunt of the backlash for this but Google was quietly mapping all of your social profiles as well.
So even if you don’t have Authorship markup on a Quora or Slideshare profile Google probably knows about it and could assign Authorship. All this data used to be available via social circles but Google removed this feature a few years ago. But that doesn’t mean Google isn’t mining the social graph.
Heck, Google could even employ usernames as a way to identify accounts from the same person. What we’re really talking about here is how Google can identify people and their areas of expertise.
Authors are People are Entities
But what if Google took another approach to identifying authors? Instead of looking for specific markup what if they looked for entities that happen to be people.
Authors are people are entities.
This would solve the adoption issue. And that’s what the Freebase Annotations of the ClueWeb Corpora (FACC) seems to indicate.
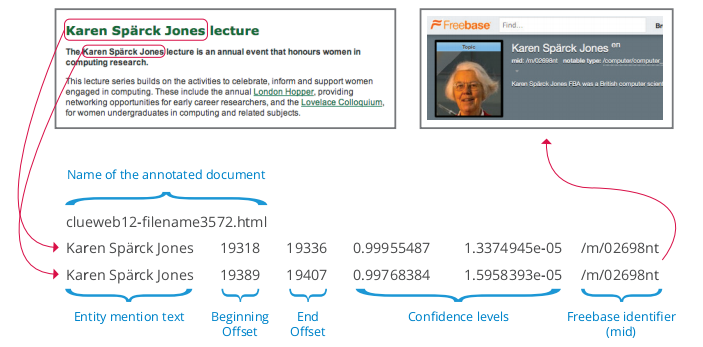
The picture makes it pretty clear in my mind. Here we’re seeing that Google has been able to identify an entity (a person in this instance) within the text of a document and match it to a Freebase identifier.
Based on review of a sample of documents, we believe the precision is about 80-85%, and recall, which is inherently difficult to measure in situations like this, is in the range of 70-85%. Not every ClueWeb document is included in this corpus; documents in which we found no entities were excluded from the set. A document might be excluded because there were no entities to be found, because the entities in question weren’t in Freebase, or because none of the entities were resolved at a confidence level above the threshold.
At a glance you might think this means that Google still has a ‘coverage’ problem if they were to use entities as their approach to Authorship. But think about who is and isn’t in Freebase (or Wikipedia). In some ways, these repositories are biased towards those who have achieved some level of notoriety.
Would Google prefer to rely on self referring markup or a crowd based approach to identifying experts?
Google+ Is An Entity Platform

While Google might prefer to use a smaller set of crowd sourced entities to assign Authorship initially I think they’d ultimately like to have a larger corpus of Authors. That’s where Google+ fits into the puzzle.
I think most people understand that Google+ is an identity platform. But if people are entities (and so are companies) then Google+ is a huge entity platform, a massive database of people.
Google+ is the knowledge graph of everyday people.
And if we then harken back to social circles, to mapping the social graph and to measuring engagement and activity, we can begin to see how a comprehensive Authorship program might take shape.
Extract, Match and Measure

Authorship then becomes about Google’s ability to extract entities from documents, matching those entities to a corpus that contains descriptors of that entity (i.e. – social profiles, official page(s), subjects) and then measuring the activity around that entity.
Perhaps Google could even go so far as to understand triples on a very detailed (document) level, noting which documents I might have authored as well as the documents in which I’ve been mentioned.
The presence of Authorship markup might increase the confidence level of the match but it will likely play a supporting and refining role instead of the defining role in the process.
Trust and Authority

I’m reminded that Google talks frequently about trust and authority. For years that was about how it assessed sites but that same terminology can (and should) be applied to people as well.
Authorship markup is but one part of the equation but that alone won’t translate into some magical silver bullet of algorithmic success. Building authority is what will ultimately matter and be reflected in any related ranking signal.
Are the documents you author well regarded by your peers? Are they shared? By who? How often? With what velocity? And are you mentioned (or cited) by other documents? Do they sit on respected sites? Who are they authored by? What text surrounded your mention?
So part of this is doing the hard work of producing memorable content, marketing yourself and engaging with your community. The other part will be ensuring that your entity information is both comprehensive and up-to-date. That means filling out your entire Google+ profile and potentially finding ways to add yourself to traditional entity resources such as Wikipedia and Freebase.
Just as links are the result and not the goal of your efforts, any sort of AuthorRank will be the result of building your own trust and authority through content and engagement.
TL;DR
The Authorship Project at Google has been abandoned. But that doesn’t mean Authorship is dead. Instead it signals a change in tactics from Authorship markup to entity extraction as a way to identify experts and a pathway to using Authorship as a ranking signal.
The Next Post: Finding A Look As Well As A Sound
The Previous Post: Crawl Optimization

21 trackbacks/pingbacks
Comments About Authorship Is Dead, Long Live Authorship
// 43 comments so far.
Elisa // October 24th 2013
Authorship is too complicated. Love when it works, but it’s hard to set up and easy to screw up. (We had trouble with it and we’re a search marketing company!) So of course adoption is low.
Awesome high school ID!!
AJ Kohn // October 24th 2013
Thanks Elisa. I found that old ID recently and thought it was pretty funny.
And I agree. The markup is too complicated for many and has a tendency to break. Even the tools used to verify Authorship provide false positives or negatives, making it even more frustrating. Long story short, Google has to find different ways to assign Authorship that don’t rely on markup.
Gregory Smith // October 24th 2013
AJ,
Glad someone took the time to point this out, but I’ve been seeing this for a while. Never really anticipated it to take effect. I never seen anything that pointed in such a direction. Thanks for taking the time to advise others on the topic.
Greg Smith
AJ Kohn // October 24th 2013
Thanks Greg.
I still believe Google wants to use some sort of Authorship or to identify experts, but they can’t get there on markup alone.
Takeshi Young // October 24th 2013
That makes sense. Even SEOs struggled for a while with figuring out the right markup for authorship. These days Google seems to pull a lot of that information automatically, although that has led to some false-positives.
AJ Kohn // October 24th 2013
Yes Takeshi. A lot of SEOs struggled (and still do) with getting it configured correctly. It’s a brittle markup.
Google often tries to fill in the gaps through inferred Authorship and they’re getting better at that but to go to the next level I think they’ll need to rely on entity identification and extraction. A system where they identify people, regardless of markup, solves the configuration and adoption issues.
Mark Traphagen // October 24th 2013
AJ,
Standing up and cheering. This will be so helpful in moving us along to the things we should be concentrating on. And it really helps to have this come from someone of your stature.
Authorship is not dead, but it is changing. We know Authorship is still an active project for Google, even if it no longer has a department of its own. It figured into Matt Cutts’s keynote at Pubcon yesterday. Google released a whole FAQ on Authorship not two months ago. And it was mentioned as helpful toward qualifying for In-Depth Articles.
That being said, and given the track record thus far as you outlined it, it makes sense to me that Authorship will be less a thing unto itself and more rolled into the overall direction Google is going, and also that they would make use of their increasing ability to identify and understand entities that goes beyond voluntary markup.
AJ Kohn // October 24th 2013
Thanks Mark.
Users respond to Authorship and are one of the few social annotations that seem to move the needle. As such, Google still believes they’re important. Never mind the landslide of content Google has to sift through. So the idea of Authorship is still of huge value.
But relying on markup alone just won’t get Google to where they want to go. So that, along with the emphasis on entities, makes me believe that there’s a larger effort to identify the right people (and sites) when returning search results.
So, yes, I think it’s been folded into a larger initiative of moving from strings to things.
Kimberly Reynolds // October 24th 2013
What I have never understood is why “important authors” (or any other type of author!) would not want to add their markup to be identified by Google. If nothing else, then just for the rich snippet.
AJ Kohn // October 24th 2013
Kimberly,
It would be nice if everyone cared but I think many aren’t that focused on how they show up. In fact, in some ways it might be the ones who care more about writing (about the content) and not how it appears in search, who might be the experts.
Should Neil deGrasse Tyson have to worry about markup when he’s writing about astrophysics?
Kimberly Reynolds // October 24th 2013
No, but Google has made it really very simple to implement authorship. I guess I have a hard time getting out of the marketing mindset. It just seems to me that if someone is going to go to the effort to product written content that they (presumably) want as many people as possible find it. Also, that they would want it to be properly attributed to them and not someone else.
Do you think the implementation ideas you put forth for Authorship will have a negative effect on the “little guy”, the writers who are not Neil deGrasse Tyson or Time Magazine?
Great post and thank you so much!
Terry Simmonds // October 24th 2013
I’ve always seen Authorship as primarily being a lure to get more people using Google+ and getting in to the habit of staying signed in to Google when general browsing.
Authorship is great when signed in and when personalization is used but I see little point in an organic search result page returning 10 authors that I do not know.
The advantage of Authorship to me is that I see content from Authors I recognise.
If I read some good content and the person has a Google+ Profile I will Circle him and then hope to see his Authorship details, but I don’t particularly want to see everyone’s Authorship details apart from people I circle or people Google think I may be interested in.
This can only happen with personalization so I would prefer to see more Authorship based on personalization and less Authorship in organic search.
AJ Kohn // October 24th 2013
Terry,
The connections between Google+, Authorship and Personalization are interesting. Too few understand that if you’re logged in and have personalization turned on then the content from people (and brands) you follow will bubble further up in your personalized results.
That could be connected to a profile that has Authorship in place or not. And like you say, Google did receive a fair amount of feedback from users who were confused by why they’d get social recommendations (aka annotations) from people they didn’t know.
What is sort of being expressed here is that personal brand means a lot. Not only that but it’s subjective. If Google understand who YOU believe is important or influential then they can create a better experience for you, rather than homogenizing for the whole.
Durant Imboden // October 24th 2013
One of the challenges Google faces with authorship is the simple fact that reputation and expertise are acquired over time. Track records matter, and most “legacy content” isn’t likely to be marked up for Google Authorship.
AJ Kohn // October 25th 2013
True Durant and even more troubling since bit rot erodes so much of the past online (i.e. – try finding something that was posted in 2005.)
That’s why identifying and extracting entities is a more scalable solution in the long-term. It’s not easy and it requires a massive graph, but it’s what is really required.
David Johnson // October 24th 2013
As long as Google continues to show my ugly mug along with the search result, I’ll continue to use it.
AJ Kohn // October 25th 2013
David,
I still recommend using the markup. There’s a clear benefit to using it. It’s just not going to be the primary way that in which a direct ranking signal is developed for Authorship.
Dan Shure // October 25th 2013
AJ
Killer read man. Do you think if a very notable person comments on your article (they have a super high author authority) this may increase the trust (err ranking) of your article? Like if Danny Sullivan, Seth Godin etc commented
-Dan
AJ Kohn // October 25th 2013
Thanks Dan.
In theory, comments by a person with topical authority should help that document rank better. The question here is about validating the identity of those persons. We’ve seen people imitate Danny and Matt Cutts frequently so simple entity extraction wouldn’t work here. Social logins provide the best potential here with Google+ comments clearly being the gold standard right now.
Warren Chandler // October 25th 2013
I wouldn’t go as far as saying RIP just yet, but you’re right in stating its ineffectiveness. It’s just another of Google’s good ideas that didn’t materialise as planned, probably through over complication.
AJ Kohn // October 25th 2013
Warren,
I think you may have misunderstood. The Authorship Project at Google has been shuttered, but the goal of using Authorship overall has not. It’s simply evolved and been folded into a much larger endeavor.
Daniel Berger // October 25th 2013
Aj hi,
i believe google is looking for articles just like this, powerful new content.
Remember that google is using many implicit algorithms for searches and i believe authorship is on of this signals. Not something you can induce by black hat tricks, but rather the steady streaming and creation of new content and time will do its own.
There is also the participation metrics, when a signal is triggered by comments or shares on post may boos your authorship as a whole, but i truly believe that also the comments or shares that trigger the popularity attribute to the participant.
AJ Kohn // October 25th 2013
Daniel,
Thanks for the kind words. I agree that thoughtful and well-written content is exactly what Google is looking to reward. Authorship may allow it to find more in-depth articles but I’m not so sure how that product is doing.
But the way in which people engage on that content is absolutely something Google is tracking. I wrote about it two years ago and the Google+ Activity API still makes clear their desire to track engagement.
Ripples is the tip of the ice berg in this regard.
Durant Imboden // October 25th 2013
I’ve been thinking more about this, and I wonder if Google isn’t simply backing off on some of more blue-sky aspects of authorship/AgentRank and viewing “author authority” as a portable, personal equivalent of domain authority–at least for the foreseeable future.
Consider a couple of hypothetical examples:
Crooningcanaries.com has published thousands articles about canaries since the site was launched in 1998. It has truckloads of inbound links from other bird and pet sites, so it’s clearly an authority on canaries.
Now we turn to an author, Betsy Byrd. Betsy has written a weekly column for Crooningcanaries.com since 1999, along with a books and articles in other media. In the pre-“author authority” era, links to her columns would have benefited Crooningcanaries.com. Assuming that Google is serious about authorship and “author authority,” Betsy will soon get her own “authority score,” which will follow her when she writes for other sites.
“How do Google+, Twitter, and other ‘social signals’ figure into this?”, you may ask. The answer may be simple: “They don’t.” Betsy’s author authority for “canaries” may derive from the fact that she’s written hundreds of articles about canaries over the last 14 years, and Web sites have linked to those articles. “Author authority” simply means that she’s now getting the same kind of respect from Google that Crooningcanaries.com has been accruing over the years.
Maybe, in time, Google will figure out a practical way to factor Google +1s, tweets, Facebook Likes, Pinterest pins, comments on blogs or forums using Google+ logins, etc. into a more ambitious “AuthorRank” or “AgentRank” scheme. But until or unless that happens, an “author authority score” that relies on traditional factors (the same factors used to judge and reward domains) can be used to benefit Google, authors, and searchers.
Brian Jensen // October 25th 2013
Hi AJ,
Fantastic post as always! With Authorship markup potentially having less influence in evaluating authorities and entities, I was hoping you may be able to offer your thoughts into the following question:
How strong of a signal do your feel Authorship markup (more specifically the links pointing back to a G+ profile) is (or was) when evaluating the authority of an author – more specifically, do you feel this may have influenced visibility in personalized search?
I’ve also wondered if facial recognition software could at some point come into play in helping Google associate content back with authors.
Thanks again for your insight and contributions to the community!
Rick // October 25th 2013
8 out of the next 10 posts in the G+ community will relate closely with one of the two following flawed thought processes:
a) Claiming authorship is a requisite to future organic search traffic success
b) Adding the markup to your pages should automatically display your avatar in the search results
I’m an advocate for utilizing the markup appropriately and the residual benefits it may bring. But by no means is it the silver bullet so many are looking for. I think some of the confusion comes from the comment from Eric Schmidt suggesting there was no future in anonymous content on the web. This of course scared the bejesus out of writers who use pseudonyms.
Rest assured folks, if you have an audience you’ll be just fine with or w/o Authorship. Eric was referring to simple words on a page written by an un-identified author where no connection can be made between them and expertise or credibility.
I hope this post received the citations it deserves.
Pepper Oldziey // October 25th 2013
AJ I love the word play. I love the authorship photos. They work. Slowly, as people begin to figure out how we get them, they will learn about Google+. It makes sense not to devote resources for a time to move a project that is not yet ready to move forward. The people are slow to catch on. Then they can.
I agree with you and Mark that it is better to focus on other topics in active motion during this time. Then suddenly, out of the blue, the new benefits of authorship will explode our world again. I think we forget how far out there this high level of discussion is from the normal understanding of the business world at large.
Many people are just figuring out Google what? what is Google+? as was shared with me on several question cards at a business luncheon talk I gave today. Once the average business person catches on, then it will make more sense as an achievement all can aspire to and benefit from.
Morgan // October 27th 2013
I’m of the belief that authorship is still very important and will continue to use it.
Thanks
Morgan
Susan // October 28th 2013
I’m just a normal blogger who tries to read this type of stuff and get it. Some of it I get, some I don’t, but I try! My question is: I do have authorship set up and was recently told that I should put a byline and the authorship code into every blog post that I create. Should I still do that given this information?
Jason // November 04th 2013
For me, it was not presented corerclty for the lay person to understand and implement. I love all the logic and examples to show it’s benefit, which I agree with.
I think they failed on easy implementation tho. K.I.S.S.
Jason // November 04th 2013
On one hand this is good news that authorship is dead – it’s so difficult to implement as others have mentioned. On another, it’s frustrating that so many changes are occuring! Can’t they just stick to something and not change things always!
Dima Midon // November 05th 2013
Sadly, but true. Anyway i’m still happy with that heat-map you attached. People will still get more clicks with they heads in snippets. 🙂
Steven Washer // November 05th 2013
Regardless of the status of the Authorship program, the benefits of having your thumbnail show up in the SERP next to your article is clear. People are more likely to click on an image than a listing without one.
You get that by using the markup in every post. You also get it by making a simple comment in G+. I think people are going to come to the realization that going forward as an author without a G+ account is kind of an uphill battle, especially if you haven’t been writing online since 1999.
Bruce // November 05th 2013
I think the best is to take advantage of these things when they happen, The eye tracking graphic says it all and that’s why I’m having a seminar about Google Authorship to get more user adoption for my local clients.
Interneta mārketings // November 05th 2013
Amazing article. 5 stars out of 5. I never looked at authorship like you just described, but I think that you are 99% right on this.
Waskita // November 05th 2013
I fail to use authorship markup. Maybe it’s because I use a black and white photo.
And I know there are many people who use somebody’s else photo to use on their profile; Google approve it, and that’s make me sad
Kevin Pike // November 05th 2013
I’ll play devil’s advocate here… In my view, the Google Authorship project is graduated – not abandoned. Once the markup is established (and people realize how easy it is to use) I don’t think you would need someone like Othar Hansson to babysit this project anymore.
I think Google is smart to go beyond Google+ to the social graph to help them find authors who are not using Google+. Ultimately this knowledge will help Google establish even more in-depth Author Rank algorithms.
Time will tell, overall great posts!
Alex Schenker // November 06th 2013
I think they’ll iron out the kinks and authorship will stay strong. They may find a way to “verify” classic authors that have a strong following but no G+ profile similar to the way celebrity Twitter accounts are verified. And with time and the move to digital book formats, authors will be forced to move online to establish their legitimacy/following.
Dr. Sass Moulavi // December 03rd 2013
Authorship has helped us get better rankings, more traffic and better exposure. i think it’s a great thing. I’m surprised by how many other business don’t verify their authorship.
Tommy Landry // December 19th 2013
I tend to agree with Kevin’s commentary, although the fact that publisher markup is available and still hasn’t been fully developed (or maybe just not explained to us yet) makes me take pause when reading this post.
Overall, I and my clients have seen positive results from authorship. The SPYW impact is great for those of us who stay active online (since our posts show up higher for our social graph), and the CTR benefits are easy to see with before / after analysis.
That leads me to side with the “graduated” comment. Of course, we’ll see what happens with publisher markup. If it turns into something important (and I think it will), we’ll know this initiative is still alive and well.
Adam Beaumont // January 23rd 2014
Unbelievable, I did not see this coming and now my picture has disappeared. I write on 3 different websites and each one is now not showing any Author Snippets, I am not impressed.
steph // March 20th 2014
authorship is a HUGE opportunity for local. when it works, it’s amazing. i do websites for optometrists, and click through & conversion of a result w/ a pic vs. w/out is a no-brainer.
Barry Livingstone // January 10th 2015
I think one of the lessor internal outcomes for Google on this authorship project has been the massive amount of human behavioral research data they can mine based on how users responded to author credits in search results… and to a lessor extent how SEO “experts” jumped through hoops to takes advantage of it.
Sorry, comments for this entry are closed at this time.
You can follow any responses to this entry via its RSS comments feed.